
System Weakness isn’t always about a 0-day vulnerability or an unpatched server. Often, the most devastating system weaknesses are architectural.
Picture this: A sudden spike in traffic hits your API. Your database connection pool maxes out. Queries start timing out. The web server threads get blocked waiting for the DB to respond. Within seconds, the entire system collapses under its own weight. This is a classic Cascading Failure, and it’s the nightmare of every backend engineer.
To truly understand how to mitigate this, reading about it isn’t enough. You need to see it break.
That’s why I built an Interactive Architecture Simulation Lab (running entirely in your browser) to visually demonstrate how architectural choices either cause — or prevent — catastrophic system failures.
The Anatomy of a System Weakness: TCP Exhaustion & The DB Bottleneck
In a traditional synchronous REST API, every incoming request maps directly to a database connection. Under normal load (e.g., 50 Requests/sec), a standard PostgreSQL pool handles this seamlessly.
But what happens when load spikes to 1,000 Req/s?
1. The Node.js application attempts to open 1,000 concurrent TCP connections to the Database.
2. The Database hits its “max_connections ”limit (default in Postgres is often 100).
3. The API layer pool throws the dreaded FATAL: “sorry, too many clients already ”or “TimeoutError: ResourceRequest timed out”.
4. Because Node.js is single-threaded, if your application logic waits on these stalled async DB calls without proper timeout implementations, the Event Loop gets blocked. Memory usage spikes (OOM), and the server crashes.
[ERROR] FATAL: sorry, too many clients already
[ERROR] UnhandledPromiseRejectionWarning: SequelizeConnectionError: timeout exceeded when trying to connect
This isn’t a code bug; it is a fundamental architectural weakness.
The Architectural Cure: Decoupling with Queues
The industry-standard solution to prevent cascading failures is to introduce an asynchronous Message Broker (like Kafka or BullMQ backed by Redis).
Instead of the Web Server talking directly to the Database, it drops the payload into the Queue and immediately returns a “202 Accepted” to the client. Worker nodes then consume from the queue at a controlled pace (e.g., 500 ops/sec), protecting the Database from ever knowing there was a spike.
Proving it in the Simulation Lab
Instead of just telling you this, I want you to experiment with it yourself. I’ve integrated a Drag-and-Drop Factorio-style simulation engine into the Simulation Lab
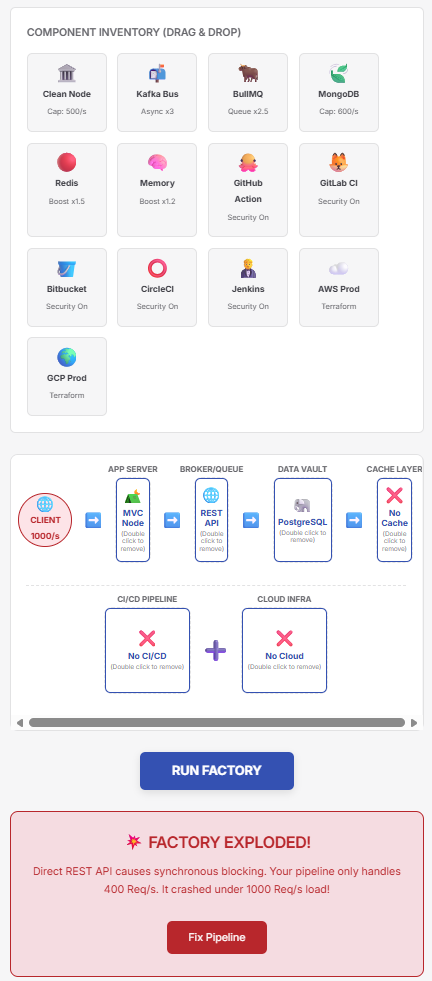
If you drag a standard “REST API” node and connect it directly to a “PostgreSQL” node and click Run Simulation at 1,000 Req/sec… the lab will throw a red alert: “System Failure: Database Overload”.
Now, fix the architecture:
1. Drop a Kafka or BullMQ node between the App and the Database.
2. Drop a Redis node for high-speed caching.
3. Click Run Simulation.
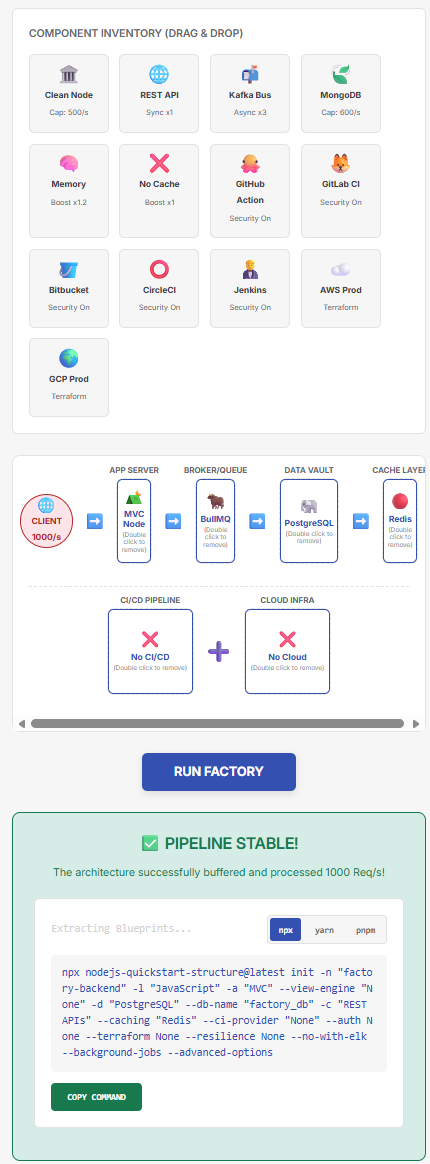
The simulation engine mathematically calculates the throughput multipliers. By decoupling the ingestion layer from the persistence layer, the factory easily processes the 1,000 Req/sec load. The system weakness has been mitigated at the architectural level.
From Simulation to Production
The best part of this Interactive Lab? It’s connected to a real, open-source scaffolding engine.
Once you’ve built a resilient pipeline in the Lab, the engine generates the exact CLI command to scaffold that architecture. For a resilient Kafka + PostgreSQL setup, it outputs:
npx nodejs-quickstart-structure@latest init -n "factory-backend" -l "JavaScript" -a "MVC" --view-engine "None" -d "PostgreSQL" --db-name "factory_db" -c "REST APIs" --caching "Redis" --ci-provider "None" --auth None --terraform None --resilience None --no-with-elk --background-jobs --advanced-options
Running this command gives you a production-ready Node.js codebase pre-configured with Kafka producers/consumers, Redis caching, and Clean Architecture patterns. Most importantly, it ships with a Zero-Vulnerability Baseline (strict dependency overrides ensure a pristine `npm audit` out of the box).
Don’t let architectural weaknesses take down your next project. Head over to the Node.js Quickstart Generator, break some architectures, and learn how to build systems that scale safely.
Why Your Node.js API Will Crash at 1,000 Req/s (And How to Fix It) was originally published in System Weakness on Medium, where people are continuing the conversation by highlighting and responding to this story.