Why the Translation Layer Needs to Reason, Not Just Route: Claude, AWS Bedrock, and the Security Boundary Question
Why the Translation Layer Needs to Reason, Not Just Route: Claude, AWS Bedrock, and the Security Boundary Question
Third in a four-part series: ReBAC Meets BSS, A Practitioner’s Blueprint for AI-Native Role-Based Access in Telco
If you have followed this series from the beginning, you will have arrived at this article with a reasonable objection forming. I know this because it is the same objection every architect I respect would raise.
Why not just build a rules engine?
Map the known TMF 672 role transitions to OpenFGA tuple mutations deterministically. Encode the UK market constraints as rules. Add the NIS2 flags as conditions. Test it thoroughly. Deploy it. Done. No AI inference cost. No latency overhead. No explainability concerns. No security boundary questions.
It is a fair objection. And for a significant proportion of role transitions it is the right answer. I want to address it directly before proposing anything else.
The Rules Engine Is Right for the 80 Percent
A deterministic orchestration service handles the majority of TMF 672 role transitions perfectly well. The transitions that are well understood, repeatable, and market-agnostic do not need a reasoning layer. They need a fast, reliable, cheap translation service.
A note on implementation language. The orchestration service in this architecture is described using Go. Go reduces the entry barrier for experimentation: its concurrency model suits event-driven workloads, its binary compilation simplifies deployment, and its standard library handles the HTTP and JSON requirements without additional dependencies. That said, the orchestration layer is not language-prescriptive. A Java-based implementation using an open-source rules engine such as Drools would handle the fast path routing logic with equal capability and may be the natural choice in organisations where Java is the established platform language. An inner-sourced rules engine built on existing enterprise frameworks is equally valid. The pattern is what matters. The implementation language is an operational decision.
A consumer upgrades from a standard plan to a premium plan. The tuple mutations are known. The product scope is fixed. The regulatory implications are unchanged. A rules engine handles this in milliseconds at negligible cost. There is no justification for sending this transition to an AI reasoning layer.
The rules engine is not the wrong answer. It is the right answer for the cases it can handle reliably. The architecture I am proposing uses it as the fast path for precisely this reason.
The problem is the other 20 percent.
Where the Rules Engine Breaks Down
A Tier-1 telco operating across multiple markets, regulatory frameworks, product scopes, and partner relationship models generates a continuous stream of role transitions that no rules engine can fully anticipate. Not because the rules engine is poorly built. Because the problem space exceeds what deterministic rules can reliably express.
Consider three examples from Article 2.
A consumer in the UK transitions to a ResellerPartner role scoped to Enterprise Broadband and VPN products under NIS2 constraints. The rules engine handles this if the transition has been explicitly modelled. But what if this is the first time this specific combination of product scope, market, and partner tier has occurred in this deployment? The rules engine has no rule for it. It fails, routes to a human, or worse, silently produces an incomplete mutation set.
A B2B2C reseller partner in mid-contract renegotiation has their tier temporarily elevated while commercial terms are agreed. The elevation is conditional on milestone completion and subject to a thirty-day review. The rules engine cannot express conditional, time-bounded, milestone-dependent tuple mutations. It was not designed to. The problem requires contextual reasoning about the business state, not pattern matching against pre-encoded transitions.
An enterprise account mid-migration between two connectivity products holds a complex authorization state that exists nowhere in the rules catalogue because it was assembled from a sequence of transitions that individually were routine but in combination produced a novel permission configuration. Resolving it requires understanding the history of how the account arrived at its current state, not just the current event.
In a Tier-1 operator processing thousands of role transitions daily, 20 percent is not a small number. And the transitions in that 20 percent are disproportionately the ones with the highest commercial stakes, the most complex regulatory implications, and the greatest potential for authorization drift if handled incorrectly.
This is where the reasoning layer becomes necessary. Not as a replacement for the rules engine. As the complement to it.
The Hybrid Architecture: Fast Path, Slow Path
The architecture that fills the broken arrow from Article 2 is a hybrid. Not AI instead of rules. AI alongside rules, each handling the subset of the problem it is best suited for.
Here is how it works end to end.
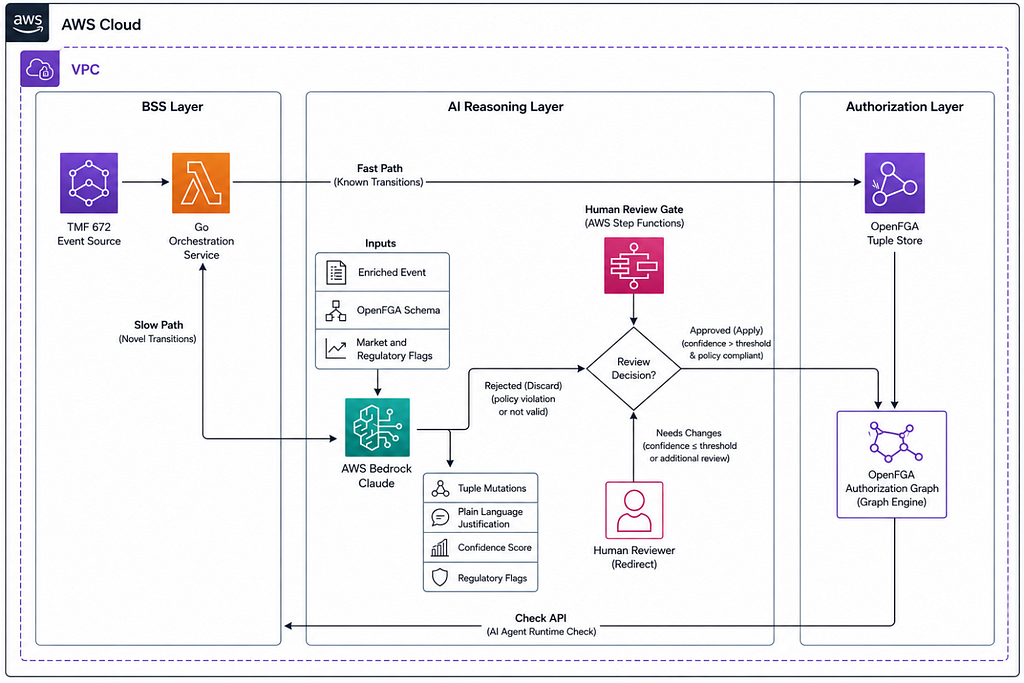
A TMF 672 role change event fires. The orchestration service receives it, validates it against the TMF 672 schema, and enriches it with two pieces of context retrieved from internal sources: the current OpenFGA tuples held by the party, and the market and regulatory flags applicable to this transition.
The enriched event reaches a routing decision. The orchestration service checks a rules cache keyed on the combination of previous role, new role, market, and regulatory tier. In a fresh system the cache is empty and every transition goes through the slow path. This is correct and expected. The cache populates over time through operational learning, which I will describe shortly.
If the transition pattern exists in the cache with a promoted confidence value, the fast path fires. Pre-validated tuple mutations are served directly. The OpenFGA Write endpoint is called immediately. Claude is never invoked. No review gate approval is required. The audit trail records the fast path execution.
If the transition is novel or not yet in the cache, the slow path fires. The enriched event is sent to Claude on AWS Bedrock. Claude receives three inputs: the enriched role transition event in structured form, the current OpenFGA relationship schema for this deployment, and the relevant market and regulatory flags. It reasons about which tuple mutations are required, returns structured output containing the mutations, a plain language justification, a confidence score between zero and one, and any regulatory flags raised.
The Two Confidence Scores and What They Each Do
This is worth being precise about because they are different values doing different jobs.
Claude’s runtime confidence score is returned by Claude on every slow path inference call. It reflects Claude’s self-assessed certainty about its proposed mutations given the context it received. Factors that push it higher include clear unambiguous role semantics, obvious schema mappings, and simple single-layer transitions. Factors that push it lower include novel market and regulatory combinations, complex multi-layer B2B2C transitions, and ambiguous current tuple states. This score routes the output through the human review gate tiers and is then logged to the audit trail. It is consumed by the slow path only and does not persist beyond that inference call.
The promoted cache confidence is a separate value assigned by the orchestration service when a slow path output is promoted to the fast path rules cache. It is a fixed high value, typically 0.99, assigned after a transition pattern has accumulated a defined number of consistent human approvals without modification. It signals that this mutation set has been operationally verified and is trusted for deterministic execution without Claude or a review gate.
The fast path never uses Claude’s runtime confidence. The slow path never uses the promoted cache confidence. They operate in separate parts of the architecture and serve separate purposes.
A structural validation step in the orchestration service adds a second signal alongside Claude’s runtime confidence. Before routing through the review gate, the service checks that every proposed tuple type exists in the OpenFGA schema and that every user type is valid for its assigned relation. A mutation set that fails structural validation is blocked regardless of how high Claude’s confidence score is. The combined signal gives the review gate a more robust routing basis than confidence alone.
The routing logic with both signals applied:
Structural validation FAILED
→ Block regardless of confidence score
Structural validation PASSED + confidence >= 0.90
→ Lightweight review, fast approval expected
Structural validation PASSED + confidence 0.70 to 0.89
→ Standard review queue
Structural validation PASSED + confidence < 0.70
→ Deep review or block pending expert assessment
The Learning Mechanism: How the Cache Populates
The system improves over time through operational learning, not model retraining.
When a slow path output for a specific transition pattern has been approved by a human reviewer a defined number of times without modification, the orchestration service promotes that pattern to the fast path rules cache. The TransitionKey, a combination of previous role, new role, market, and regulatory tier, is added to the cache with the pre-validated mutations and a promoted confidence of 0.99.
The next time that exact transition pattern arrives, the fast path serves it directly. Claude is not invoked. The review gate is bypassed. The audit trail records the fast path execution.
This has two practical consequences. First, the system gets faster and cheaper as the cache grows. The proportion of transitions requiring Claude inference decreases as the deployment matures. Second, the rules engine eventually reflects the real-world authorization semantics of this specific deployment rather than a theoretically authored set of rules that may not match operational reality.
The cache starts empty in every fresh deployment. Every transition begins on the slow path. This is not a limitation. It is the mechanism by which the system learns from its own operational history.
The Human Review Gate
The review gate is the enterprise trust mechanism that makes this architecture deployable today rather than in a future state where AI reasoning is trusted to operate without oversight.
It is not an admission that Claude cannot be trusted. It is a configurable risk control that applies the same tiered governance logic enterprises already use for financial approvals, change management, and access control requests. The pattern is familiar. The application to AI reasoning output is new.
Three tiers in the review gate:
High confidence transitions with no regulatory flags proceed to lightweight review. A reviewer sees Claude’s plain language reasoning, the proposed mutations in human-readable form, and approves or dismisses within a short window. The expectation is that the vast majority of slow path transitions fall here.
Medium confidence or medium severity regulatory flags route to a standard review queue with a defined response window. The reviewer examines the proposed mutations in detail before anything is written.
Low confidence or high severity flags are blocked pending senior review with a shorter response window. Timeout escalation prevents indefinite stalling on a difficult case.
The reviewer does not need to understand OpenFGA internals. Claude’s plain language justification does that translation. The reviewer is making a business and compliance judgement, not a technical one.
Approved outputs increment the approval count for their TransitionKey. At the promotion threshold, the pattern moves to the fast path. The gate that governs slow path outputs today is building the fast path that makes them unnecessary tomorrow.
Why This Is AI-Native, Not AI-Bolted-On
The distinction matters and is worth being precise about.
Most enterprise AI proposals add a conversational interface on top of an existing system. The underlying system is unchanged. The AI is a layer of convenience. Remove it and the system still functions, perhaps less pleasantly, but functionally.
What this architecture proposes is different. The AI reasoning layer is performing a function the system cannot perform without it. The translation from TMF 672 role semantics to OpenFGA tuple mutations across novel, multi-market, regulatory edge cases requires contextual reasoning that cannot be fully encoded as deterministic rules. Remove Claude from this architecture and the system does not degrade gracefully. It falls back to the manual processes described in Article 2. The same trouble tickets. The same propagation lag. The same operational risk the architecture was designed to eliminate.
The test for AI-native architecture is precise: is the AI doing something the system genuinely cannot do without it? In this architecture, for the subset of transitions that reach the slow path, yes.
The Security Boundary Question
Before an enterprise security team approves any architecture involving an external AI API, they will ask one question with predictable precision.
Does using Claude mean our party identity data leaves our cloud boundary?
It is the right question. TMF 672 role transition events contain party identifiers, market data, product scope, and regulatory context. This is commercially sensitive identity information subject to GDPR, NIS2, and telecoms-specific regulatory obligations. Sending it to any external API is a data boundary crossing that requires explicit risk assessment and approval.
The answer depends entirely on which deployment pattern you choose. There are four options and they are not equivalent.
Pattern 1: Direct Claude API
The TMF 672 event is sent directly to api.anthropic.com. The raw event including party identifiers crosses your cloud boundary to Anthropic-operated infrastructure. This is unacceptable for production. Your data protection officer will correctly block it. Do not use this pattern for PII-containing payloads.
Pattern 2: Anonymised Payload to Direct Claude API
Party identifiers are stripped before the boundary is crossed. Claude receives role transition semantics, product scope categories, and regulatory tier information only. A re-hydration function inside your boundary maps Claude’s output back to the actual party before writing to OpenFGA.
This is viable with trade-offs. Claude’s reasoning quality is reduced because it lacks the full party context that sometimes informs authorization decisions. The re-hydration logic adds complexity. And the anonymisation step must be audited carefully: partial anonymisation that leaves inferrable identifiers is not anonymisation.
Pattern 3: AWS Bedrock Standard
Claude inference runs within your AWS environment. The TMF 672 event never leaves your AWS boundary. AWS is the data processor under your existing AWS Data Processing Agreement. Anthropic never receives the data. Full CloudTrail audit logging of every inference call is available natively. Your existing AWS security controls wrap the entire flow.
This is the production-ready pattern for most enterprise environments. The data boundary question has a structural answer, not a configuration-dependent one. It resolves entirely because Anthropic-operated infrastructure is simply not in the data path.
Pattern 4: AWS Bedrock with VPC Private Endpoint
The same as Pattern 3 but inference traffic is routed through a VPC private endpoint, meaning it never traverses the public internet even within AWS. The TMF 672 event travels from your application over AWS private network infrastructure to Bedrock and back. Zero public internet exposure at any point.
This is the maximum security posture and the pattern I recommend for production deployments in regulated telco environments. It is defensible to a CISO, a Data Protection Officer, and an external auditor under GDPR and NIS2. The additional infrastructure overhead is a VPC endpoint configuration, which is a one-time setup within your existing AWS environment.
Add Bedrock Guardrails to either Bedrock pattern and you gain a native PII detection and redaction layer as an additional safety net. Bedrock Guardrails can detect and flag PII in inference payloads before they reach the model, adding a second layer of protection alongside your orchestration layer’s enrichment and validation logic.
A Note on Claude Platform on AWS
A relevant development worth addressing directly. Claude Platform on AWS reached general availability in May 2025, making it a current option for architects evaluating Claude deployment patterns.
The fundamental distinction is the operating model. AWS Bedrock is AWS-operated. Data stays within the AWS boundary. Anthropic never touches it. Claude Platform on AWS is Anthropic-operated. Data crosses to Anthropic-managed infrastructure. AWS handles authentication and billing only.
For TMF 672 role transition events containing party identity data, AWS Bedrock remains the correct recommendation. The AWS DPA is already in place as part of your existing AWS commercial relationship. The data boundary is structural. No separate Anthropic DPA review is required from your legal and procurement teams.
Claude Platform on AWS becomes worth evaluating in two specific scenarios. First, if you implement full anonymisation before the reasoning call, in which case no PII crosses the boundary and Claude Platform on AWS gives you same-day access to the latest Claude features without Bedrock’s feature lag. Second, as your architecture matures and the reasoning layer expands beyond tuple mutations into more complex agentic workflows where Claude’s Agent Skills and MCP connectors become relevant.
For the architecture described in this series, AWS Bedrock with VPC private endpoint is the right choice. Claude Platform on AWS is worth keeping on your evaluation list for future phases.
The Audit Trail as a First-Class Output
The second most consistent enterprise objection to AI reasoning layers is explainability. Not security. Explainability.
How do you audit what the AI decided and why? How do you respond to a regulator who asks why a specific authorization change was made? How does your compliance team demonstrate that authorization decisions were made with appropriate governance?
In this architecture the audit trail is not a secondary consideration added to satisfy compliance requirements. It is a designed output of the reasoning layer itself.
Every Claude inference call returns a plain language reasoning field alongside the tuple mutations. This field explains, in language a compliance officer can read without understanding OpenFGA internals, exactly why each tuple was created or revoked. It is logged alongside the mutations, the original TMF 672 event, the confidence score, the structural validation result, and the CloudTrail inference record.
The complete audit record for any authorization change answers four questions: what role transition triggered the change, what authorization mutations were made, why those specific mutations were made, and which human reviewer approved them before they were written.
This directly addresses the explainability requirements under GDPR Article 22, NIS2 audit obligations, and the telecoms-specific regulatory frameworks that govern authorization decisions in Tier-1 operator environments.
The Investment Case
This is not an AI experiment. It is authorization infrastructure that happens to use AI reasoning for the subset of transitions that deterministic rules cannot handle reliably.
It keeps all party identity data inside your existing AWS security boundary. It produces an audit trail that satisfies regulatory explainability requirements. It has a human review gate that preserves governance without sacrificing automation. It starts on the slow path and learns its way to the fast path through operational approval cycles. And it directly unblocks the enterprise AI agent deployments your organisation has already committed to but cannot yet deploy safely without a dynamic, context-aware authorization layer underneath them.
The AI agents you are building are only as trustworthy as the authorization layer they operate on. That layer cannot be static. It cannot be manually maintained. And it cannot be built from deterministic rules alone when the problem space exceeds what rules can reliably express.
Next week I close the series with the implementation blueprint and what I learned designing it. The build continues beyond the series.
Soumit Saha is a Digital Platform and Technical Architect with 25 years of experience in telco, cloud, and enterprise integration. He has led the adoption of TM Forum Open APIs across multiple markets and holds TOGAF 9, ODA Practitioner, and AWS Cloud Architect certifications. This series represents his personal architectural thinking and does not reflect the views or systems of any employer.
Next: Article 4, The Authorization Gap, Closed: A Blueprint for TMF 672, OpenFGA, and Claude on AWS Bedrock
Originally published at https://www.linkedin.com.
Why the Translation Layer Needs to Reason, Not Just Route: Claude, AWS Bedrock, and the Security… was originally published in System Weakness on Medium, where people are continuing the conversation by highlighting and responding to this story.