How AI Coding Agents, MCP Servers, Executive Shadow Engineering, and Compromised Model Channels Could Turn Trusted Workflows into Distributed Attack Infrastructure

I am a developer.
That is why this topic does not feel abstract to me.
This article is discussed and written with ai ;)
A developer machine is not just a laptop.
A CEO laptop is not just a laptop.
A coding agent is not just autocomplete.
An MCP server is not just an integration layer.
And a model provider is not just an API endpoint.
The dangerous question is not whether artificial intelligence will one day become powerful.
The dangerous question is whether we are already connecting AI systems to places that are powerful.
Source code. Cloud accounts. CI/CD systems. Slack. Jira. GitHub. GitLab. Databases. Customer data. Logs. Production APIs. Finance systems. DNS. Kubernetes clusters. Internal documentation. Executive e-mail. Vendor portals. Package registries. Support tools. Identity providers. Private repositories. Local .env files. SSH keys. OAuth sessions. Persistent browser cookies. Service accounts.
The model does not need to own any of these things.
It only needs to be connected to a tool that can reach them.
That is the shift.
For years, we discussed AI security as if the central question were: Can the model produce dangerous text? That is still a serious question. But it is no longer the deepest one. Once AI systems become agents, once they gain tools, once they run inside IDEs, terminals, cloud dashboards, internal automations, or server-side MCP bundles, the important question becomes:
What can this system do if its next instruction is wrong, manipulated, poisoned, compromised, or maliciously steered?
This article is about that boundary.
It is about AI coding tools like OpenCode, Claude Code, Cursor-like IDE agents, Copilot-style assistants, CLI agents, MCP toolchains, server-side agent bundles, executive no-code automations, and the model/provider channels behind them.
It is also about something more general: agentic supply chain risk.
Not the old supply chain alone. Not just npm, PyPI, Docker, GitHub Actions, CI/CD, or a compromised dependency. Those still matter. But agentic development introduces a new layer before the commit, before the package, before the build, before the deployment.
The model response can become part of the supply chain.
The agent decision can become part of the supply chain.
The tool permission can become part of the supply chain.
The MCP server can become part of the supply chain.
The developer workstation can become part of the supply chain.
The CEO laptop can become part of the supply chain.
The provider channel can become part of the supply chain.
The danger is not that developers are the problem. They are not. The danger is that developers, CTOs, founders, and executives sit in places where trust already exists. Their tools inherit that trust. Their agents operate near that trust. Their credentials open doors that normal software never sees.
The door is not the developer.
The door is the tool.

1. The thesis
Here is the thesis in its strongest form:
AI does not need to become an attacker to change cybersecurity. It only needs to become the interface through which trusted systems act.
A compromised AI coding agent does not need to invent a new vulnerability. It can recommend a dependency. It can change a build file. It can suggest a CI/CD workflow. It can modify tests. It can add logging. It can read local files. It can invoke tools. It can ask for permissions. It can generate scripts. It can open pull requests. It can use an MCP server. It can query a database. It can interact with external APIs. It can trigger an automation. It can persuade a human to click “approve.”
A compromised model provider does not need to own every customer system directly. It can influence the agents that customers already installed.
A compromised MCP server does not need to break every downstream system. It may already hold service credentials that downstream systems trust.
A compromised executive laptop does not need to contain production code. It may contain authority: e-mail, documents, chats, contracts, approvals, passwords, browser sessions, admin consoles, vendor portals, and the ability to tell other people what to do.
This creates a new security category:
Agentic Supply Chain Risk is the risk that AI-enabled tools, model providers, agent hosts, MCP servers, plugins, IDE extensions, CLIs, automations, or connected workflows become part of the software and organizational supply chain, allowing compromised or manipulated AI channels to influence trusted systems through delegated capabilities.
This is not science fiction. It is not a claim that every AI tool is malicious. It is not an argument against using AI. It is an argument that we are treating some of these systems as productivity tools while they are quietly becoming control surfaces.
A calculator does not need an OAuth token.
Autocomplete does not need a shell.
A grammar checker does not need access to Kubernetes.
A chatbot does not need your CI/CD secrets.
An agent often asks for all of these.
That is the boundary.
2. Why this is not anti-developer
A bad framing would be:
Developers are careless. Developers are the attack surface. Developers are dangerous.
That is not the argument.
The better framing is:
Developer environments are powerful. Developer tools are becoming agentic. That combination creates a high-value security boundary.
A developer is not dangerous because they write code. A developer is security-relevant because their environment often sits next to code, secrets, infrastructure, deployment paths, architecture knowledge, and organizational trust.
The same is true for CTOs, founders, and executives, but with a different kind of power. The developer has technical capability. The executive has authority. AI tools can convert authority into capability.
That is new.
Before AI agents, a non-technical CEO could instruct a team, approve a tool, or forward a file. With agentic systems, the same CEO may now generate scripts, connect SaaS systems, build internal automations, query company data, manipulate spreadsheets, connect private APIs, or deploy “just a prototype” with credentials they do not fully understand.
Again: the person is not the problem.
The problem is the transformation of role power into tool power without matching security architecture.
A developer with an agent is a privileged technical node.
A CTO with an agent is a privileged architectural node.
A CEO with an agent is a privileged authority node.
A founder with an agent may be all three.
The security question becomes: What does the agent inherit from the human context?
Not just permissions. Also trust. Context. Reputation. Urgency. Social authority. Access patterns. Communication channels. Institutional assumptions. Saved browser sessions. Local caches. API keys. OAuth grants. SSH agents. Git identities. Package tokens. Cloud CLIs. Documents. Slack channels. Meeting notes. Strategy files.
This is why the classic phrase “human in the loop” is no longer enough. The human may be in the loop, but the loop itself may be too complex for the human to reconstruct.
3. From software supply chain to agentic supply chain
Software supply chain security used to focus on artifacts and dependencies.
- Who published this package?
- Who signed this release?
- What is inside this container?
- Which dependency pulled this transitive dependency?
- Who changed the build workflow?
- Which GitHub Action ran?
- Which token could the pipeline access?
- What SBOM describes this artifact?
All of that still matters.
But AI coding agents move the risk upstream.
The supply chain no longer starts when a package is built. It may begin when a model suggests a package. It may begin when an agent edits a config file. It may begin when an IDE extension reads a repository. It may begin when an MCP tool description enters the agent context. It may begin when a developer asks: “Can you fix this test?” and the agent modifies a workflow that later touches production.
A modern agentic development flow may look like this:
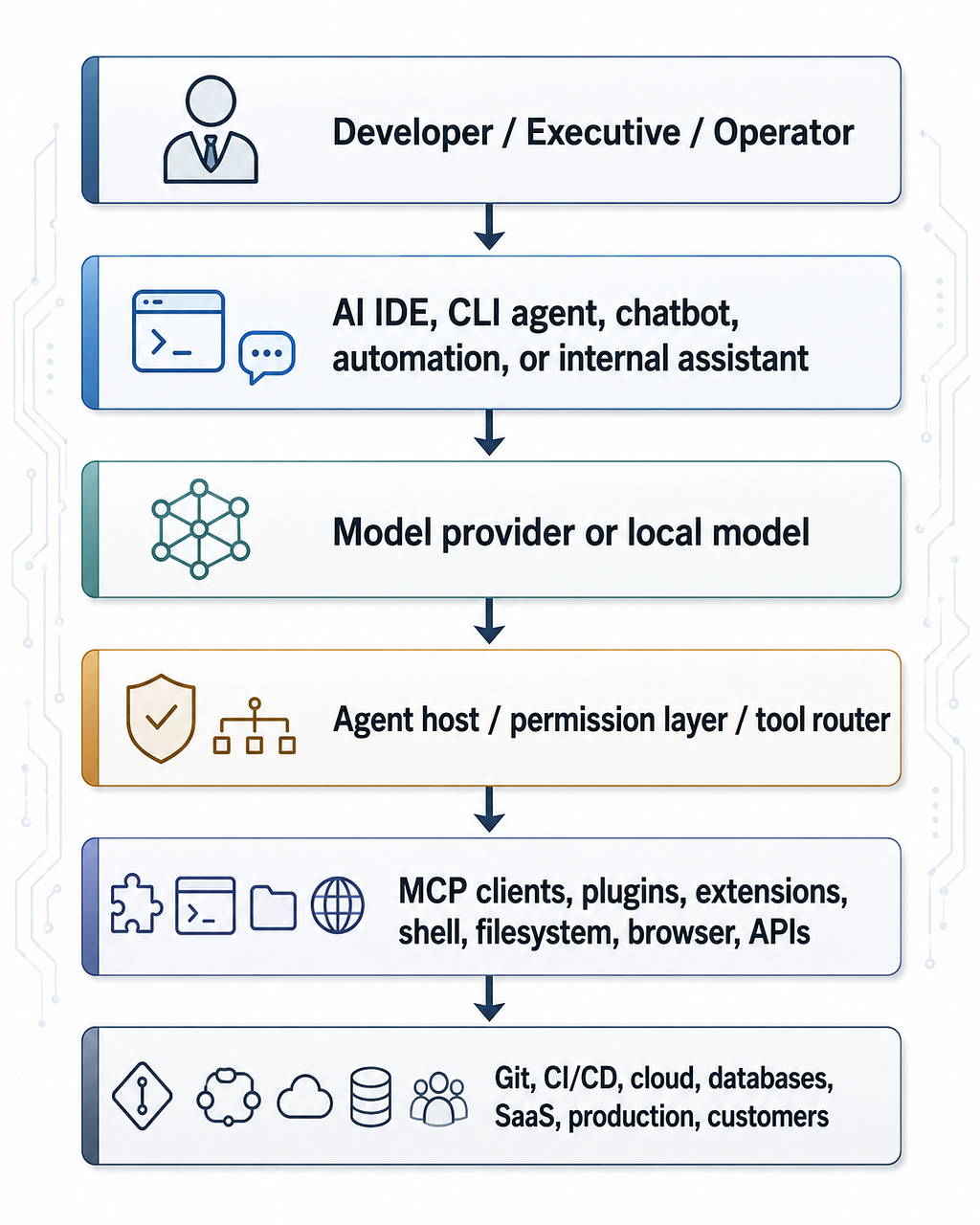
Every arrow is a trust boundary.
Every trust boundary can fail.
Every integration may expand the blast radius.
- The model provider may be honest but vulnerable.
- The IDE may be legitimate but over-permissive.
- The MCP server may be useful but over-scoped.
- The plugin may be popular but compromised.
- The tool description may be poisoned.
- The user may approve something they do not understand.
- The CI/CD system may trust a change because it came from a known developer.
- The organization may trust the executive because the e-mail came from the right inbox.
This is why agentic supply chain risk is not merely another variant of prompt injection. Prompt injection is one input path. The deeper issue is the capability chain.
An Agentic Capability Chain is the full path from model output to real-world action: model, host, permissions, tools, credentials, downstream systems, and human approval.
If that chain is weak, the model does not need to be “evil.” It only needs to produce or relay an instruction that the chain executes.
4. The real-world basis
The public evidence is still incomplete, but the pattern is no longer imaginary.
OWASP’s Top 10 for LLM Applications includes categories that map directly onto this article’s threat model: prompt injection, supply chain vulnerabilities, sensitive information disclosure, and excessive agency. OWASP defines excessive agency as the condition where an LLM-based system can perform damaging actions because it has too many functions, too many permissions, or too much autonomy in response to unexpected, ambiguous, manipulated, or malicious model outputs.
Source: OWASP Top 10 for Large Language Model Applications and OWASP LLM06: Excessive Agency
MCP, the Model Context Protocol, explicitly exists to connect LLM applications to external data sources and tools. Its specification describes tools that can be invoked by language models and resources that can expose context such as files, database schemas, or application-specific information.
Source: MCP specification, MCP tools, MCP resources
The MCP security documentation addresses risks such as confused deputy problems, token passthrough, token audience validation, session hijacking, and the need to avoid treating model-driven tool use as inherently trusted. The authorization spec says MCP servers must validate that tokens were issued specifically for their use, and it highlights why token passthrough is forbidden.
Source: MCP Security Best Practices, MCP Authorization
CISA, NSA, and international partners released guidance in 2026 on the careful adoption of agentic AI services. The guidance recommends aligning agentic AI risks with existing security models and warns against granting agentic systems broad or unrestricted access, especially to sensitive data or critical systems.
Source: CISA: Careful Adoption of Agentic AI Services, NSA release
Google Threat Intelligence Group reported in May 2026 that adversaries are using AI for vulnerability exploitation and initial access, and it described AI-enabled malware such as PROMPTSPY as a sign of movement toward autonomous malware operations where models interpret system states, generate commands dynamically, and manipulate victim environments.
Source: Google Threat Intelligence: AI vulnerability exploitation and initial access
Anthropic reported in 2025 that it disrupted what it described as the first reported AI-orchestrated cyber espionage campaign, where attackers used agentic capabilities not merely as advice but to execute parts of cyberattacks.
Source: Anthropic: Disrupting the first reported AI-orchestrated cyber espionage campaign
Microsoft’s Digital Defense Report 2025 states that AI is benefiting both defenders and threat actors, and that threat actors are using techniques such as AI-automated phishing and multi-stage attack chains while still often exploiting known security gaps.
Source: Microsoft Digital Defense Report 2025
GitGuardian’s 2026 State of Secrets Sprawl report found 28,649,024 new secrets detected in public GitHub commits in 2025, a 34% year-over-year increase, and highlighted the role of AI adoption and faster software production in the expanding secrets problem.
Source: GitGuardian State of Secrets Sprawl 2026
GitHub describes push protection as a mechanism designed to prevent hardcoded credentials such as secrets or tokens from being pushed into repositories in the first place.
Source: GitHub: About push protection
OpenCode’s documentation shows the practical shape of an AI coding agent’s capability surface: permissions around file reads, edits, globbing, grep, bash, subagents, skills, LSP queries, and extension through custom tools or MCP servers.
Source: OpenCode permissions, OpenCode agents
None of these sources alone proves the worst-case future. That is important. A serious article should not pretend that every possible scenario is already happening at scale.
But together they show the direction:
- LLM systems are becoming agentic.
- Agentic systems are being connected to real tools.
- Real tools carry real permissions.
- Attackers are already using AI to scale and adapt cyber operations.
- Secrets exposure is increasing in AI-accelerated software development.
- Security agencies are explicitly warning against broad agent access.
- MCP and similar protocols are becoming standard interfaces between models and systems.
The point is not panic.
The point is architectural honesty.

5. What makes agentic tools different from normal software tools?
Normal tools are dangerous when compromised. That is not new.
- A malicious browser extension can steal cookies.
- A malicious npm package can run install scripts.
- A malicious CI/CD action can exfiltrate secrets.
- A malicious IDE extension can read local files.
- A malicious cloud token can access infrastructure.
So what is new?
The new element is not raw capability. The new element is interpretive autonomy inside a trusted workflow.
A traditional tool usually does what its code says. That is bad enough if it is malicious. An agentic tool combines code with interpretation. It observes context, receives instructions, decides which tool to call, transforms vague goals into steps, and may request or use permissions dynamically.
That makes the attack surface wider because the instruction surface becomes part of the execution surface.
A file can become an instruction.
A README can become an instruction.
A Slack message can become an instruction.
A Jira ticket can become an instruction.
A database record can become an instruction.
A support e-mail can become an instruction.
An MCP tool description can become an instruction.
An error log can become an instruction.
A generated test failure can become an instruction.
A maliciously crafted dependency document can become an instruction.
This does not mean the agent must obey every hostile string. It means the system has to treat every context item as potentially adversarial, because the model is built to interpret context.
That is the security inversion:
In traditional software, data should not become code.
In agentic systems, data often becomes intent.
And intent is the thing the agent acts on.
This is why prompt injection is not “just prompts.” It is a symptom of a deeper design problem: the system mixes instructions, data, tool descriptions, retrieved context, user intent, and policy into one reasoning space, then asks a model to decide what matters.
That can work impressively.
It can also fail quietly.
6. The model cannot give itself permissions — unless the architecture lets it
A very important question is whether a hacked model or provider could simply grant itself permissions.
The precise answer is:
In a well-designed architecture, no.
In a weak architecture, indirectly, effectively, and sometimes invisibly, yes.
The model should not be the authorization authority.
A safe architecture separates intent from authorization:
- Model output = untrusted intent
- Authorization = deterministic control plane
- Execution = policy-checked capability
- Audit = immutable evidence
The model may request: “Call tool X with parameters Y.”
The system must decide: “Is that allowed for this user, this session, this data, this environment, this scope, this time, this risk class, and this downstream effect?”
If the model is also effectively deciding permissions, the architecture has already failed.
- A model should not sign tokens.
- A model should not grant OAuth scopes.
- A model should not select its own permission boundaries.
- A model should not decide whether a high-impact action requires review.
- A model should not silently upgrade from read-only to write.
- A model should not be able to bypass egress restrictions.
- A model should not choose whether logs are written.
- A model should not be the only component that explains risk to the user.
The trap is that many real systems do not fail in such an obvious way. They fail through something softer.
Permission laundering
Permission laundering happens when an agent does not create new permissions but uses existing permissions in a way that makes the action appear legitimate.
- A user allowed “check logs.”
- The tool behind that permission can also access sensitive customer records.
- The agent asks for a harmless task.
- The underlying service account has broad access.
- The action is executed through a trusted channel.
- The audit log says the trusted integration did it.
No one technically “gave the model admin.”
But the capability chain did.
Consent laundering
Consent laundering happens when the user approves a phrase, not a capability.
The UI says:
“Allow agent to improve project setup?”
The actual capability path includes editing build scripts, reading environment-adjacent files, invoking shell commands, sending telemetry, or changing CI configuration.
The human approved a story.
The system executed a capability.
Scope drift
Scope drift happens when a tool starts narrow and becomes broad over time.
- At first, the agent only reads files.
- Then it edits files.
- Then it runs tests.
- Then it installs dependencies.
- Then it accesses issue trackers.
- Then it reads logs.
- Then it connects to cloud APIs.
- Then it writes deployment config.
- Then the team adds “temporary” access to production because “we need to debug quickly.”
Nobody made one catastrophic decision.
They made twenty convenient decisions.
Stored consent abuse
Stored consent abuse happens when an old approval is reused in a new risk context.
- The user approved a connector months ago.
- The organization changed.
- The tool changed.
- The model changed.
- The vendor changed.
- The MCP server changed.
- The scope remained.
Security often fails because time changes the meaning of consent.
Host compromise
If the model provider is compromised, that is bad.
If the agent host is compromised, it may be worse.
The host may control which tools exist, how permissions are shown, which prompts are injected, which model is called, what telemetry is sent, whether local files are indexed, whether commands are auto-approved, and what counts as a user confirmation.
A model can ask.
A host can execute.
A compromised host is therefore closer to the boundary of action.
MCP server compromise
If an MCP server is compromised, the model may receive poisoned tool descriptions or malicious tool responses. The server may also have downstream credentials. If those credentials are broad, the tool can become a privilege bridge.
The model still does not create permissions.
But the MCP server may already have them.
7. MCP is not dangerous because it is bad; it is dangerous because it works
MCP is useful because it standardizes how AI systems connect to external tools and data. That is exactly why it matters for security.
- A weak integration is less useful.
- A powerful integration is more dangerous.
That is the paradox of agentic tooling.
The better the agent becomes at using tools, the more important tool security becomes. The better the agent becomes at understanding context, the more important context integrity becomes. The better the agent becomes at acting across systems, the more important identity, authorization, logging, and containment become.
MCP tools can expose actions.
MCP resources can expose context.
MCP prompts can shape behavior.
MCP servers can connect to databases, APIs, repositories, cloud systems, internal tools, files, or business applications.
When MCP is local and tightly scoped, the risk may be manageable.
When MCP is server-side and connected to production, the risk changes.
When MCP servers run with broad service accounts, the risk changes again.
When multiple models and agents use the same MCP bundle, the risk becomes systemic.
When an organization installs third-party MCP servers without clear security review, the risk becomes supply chain.
When an executive connects an agent to a live CRM, finance tool, Google Workspace, Notion workspace, Slack, or internal API, the risk becomes organizational.
When a compromised provider channel can influence many agents using similar MCP integrations, the risk becomes distributed.
This is why MCP security is not merely an implementation detail. MCP is a capability layer. Capability layers need security models.
The question should never be:
Does this MCP server work?
The question should be:
What can this MCP server reach, under whose identity, with which scopes, through which tokens, with what audit trail, under what approval policy, and what happens if the model input is hostile?
That is the correct security conversation.
8. The developer workstation as control surface
A developer workstation is not a normal endpoint.
It may contain or reach:
- source code
- private repositories
- SSH keys
- Git credentials
- package registry tokens
- cloud CLI sessions
- kubeconfigs
- .env files
- database dumps
- production logs
- customer sample data
- CI/CD configuration
- secrets in shell history
- internal documentation
- issue trackers
- Slack or Teams
- local certificates
- VPN profiles
- SSO browser sessions
- internal admin panels
- deployment scripts
This does not mean every developer has all of these. Mature organizations restrict many of them. But enough real environments still contain enough of them that developer endpoints remain high-value targets.
AI coding agents amplify this because they operate exactly where these resources live.
A local agent that can read files may encounter secrets.
A local agent that can run shell commands may invoke tools.
A local agent that can edit files may modify build paths.
A local agent that can call web resources may connect internal context to external outputs.
A local agent that can use MCP may bridge local context to remote systems.
A local agent that can launch subagents may multiply decision paths.
Again, this does not make the tool malicious. It makes the environment sensitive.
The secure default for agentic coding should be closer to:
“This is a junior external contractor in a sandbox with no secrets.”
Not:
“This is me, but faster.”
The agent is not you. It does not share your judgment, accountability, intuition, memory of organizational politics, or understanding of why a file is dangerous. It may operate under your identity, but it is not your identity.
That distinction matters.

9. The executive laptop as authority surface
If the developer workstation is a technical control surface, the executive laptop is an authority surface.
This may be even more under-discussed.
CEOs, CTOs, founders, managing directors, and senior leaders often hold unusual combinations of access:
- e-mail authority
- financial authority
- vendor approval
- admin rights in SaaS platforms
- access to HR data
- board documents
- investor information
- M&A documents
- customer contracts
- domain registrar access
- payment systems
- banking portals
- password managers
- cloud owner accounts in small companies
- GitHub organization owner permissions
- emergency override privileges
- influence over security exceptions
When executives begin using AI tools to build prototypes, automate workflows, analyze internal data, generate scripts, connect SaaS systems, or “quickly test” integrations, something changes.
They become accidental operators.
Executive Shadow Engineering is the creation or connection of technical workflows by people with high organizational authority outside the normal engineering, review, security, and governance processes.
This is not a character flaw. It is a predictable outcome of AI lowering the barrier to technical action.
- The CEO who could not write a script yesterday can generate one today.
- The founder who would have asked engineering can now connect a workflow in an hour.
- The CTO who knows enough to be dangerous may move faster than the security process.
- The business leader who wants a dashboard may upload sensitive data to an external AI system.
The real risk is the combination of power and bypass.
- An executive can approve a vendor.
- An executive can tell staff to ignore a warning.
- An executive can ask for a temporary exception.
- An executive can send a convincing instruction.
- An executive can connect a tool to sensitive data.
- An executive can accidentally normalize unsafe practice.
If that machine or account is compromised, the attacker gains more than files. The attacker gains a voice.
Business Email Compromise already shows how damaging authority abuse can be. Add AI-generated personalization, internal context, calendar awareness, document access, and the ability to generate plausible technical instructions, and the risk becomes deeper.
A compromised developer machine can change code.
A compromised executive machine can change decisions.
A compromised AI-enabled executive machine can change both.
That is a different class of blast radius.
10. The provider channel as upstream risk
Now we arrive at the largest version of the question.
What happens if the model provider, agent provider, extension provider, update channel, or tool marketplace is compromised?
This is the upstream nightmare.
Most security teams think in local terms:
- Is this developer workstation hardened?
- Is this token scoped?
- Is this repository protected?
- Is this CI/CD pipeline reviewed?
- Is this MCP server trusted?
- Is this model safe?
But if many organizations use the same agent provider, and if that agent provider can influence model responses, tool routing, system prompts, updates, permission UI, telemetry, plugins, or MCP integrations, the blast radius can become cross-organizational.
A compromised provider channel might not need to deploy obvious malware. It could manipulate behavior subtly:
- recommend weaker security defaults
- suggest unsafe dependency upgrades
- insert small insecure patterns into generated code
- encourage broad permissions
- misdescribe risks in approval prompts
- normalize logging of sensitive data
- weaken tests
- modify CI/CD workflows in ways that look useful
- suggest convenience scripts
- route data through unexpected tools
- request additional scopes under plausible reasons
- influence documentation that later agents read
- create patterns that are hard to distinguish from normal AI assistance
This is why “malware” is too narrow a word.
A hostile provider channel could operate through plausibility.
The attack would look like help.
The changes would look like productivity.
The model would sound useful.
The agent would appear to fix things.
The developer would approve.
The organization would merge.
The CI/CD system would deploy.
The customer would experience the result.
That is what makes agentic supply chain risk different.
The old fear was malicious code that looks like code.
The new fear is malicious assistance that looks like assistance.
11. AI-assisted malware and agentic botnets
When people say “AI viruses,” they often mean different things. We should be precise.
There are at least four categories:
- AI-assisted malware — malware created, modified, translated, obfuscated, analyzed, or improved with AI assistance.
- AI-enabled malware — malware that uses AI or model APIs during operation to interpret environments, generate next steps, adapt commands, or choose targets.
- AI-operated botnets — botnets whose targeting, timing, social engineering, command selection, prioritization, or evasion is partially coordinated by AI.
- Agentic capability botnets — networks of compromised or manipulated agents, tools, MCP servers, automations, or trusted integrations that act through legitimate delegated capabilities.
The fourth class is the most relevant here.
A traditional botnet is made of compromised machines.
An agentic capability botnet may be made of compromised trusted workflows.
It may include:
- AI coding agents
- IDE extensions
- CLI agents
- MCP servers
- SaaS automations
- CI/CD integrations
- support bots
- RAG assistants
- internal data agents
- no-code connectors
- cloud automation agents
- executive AI tools
- service accounts attached to agents
- browser-based assistants with enterprise access
The value of such a botnet would not primarily be CPU power.
It would be trust.
A classic botnet can send traffic.
A capability botnet can act from inside trusted systems.
A classic botnet abuses machines.
A capability botnet abuses delegated authority.
A classic botnet may be noisy.
A capability botnet may look like normal work.
This is the sentence:
The next botnet may not be made of infected computers. It may be made of trusted agents with delegated capabilities.
This is not yet the everyday reality. It is a plausible escalation path. But early signs point in the direction of AI making cyber operations more adaptive, scalable, and context-aware. Google’s reporting on AI-enabled malware and autonomous malware operations, Anthropic’s report on AI-orchestrated espionage, Microsoft’s reporting on AI-automated phishing and multi-stage attack chains, and CISA/NSA’s agentic AI guidance all point to the same transition: AI is moving from text generation into operational cyber workflows.
That does not mean attackers are omnipotent.
It means defenders should stop treating agentic integrations as harmless productivity features.

12. Worst-case scenario 1: the compromised coding-agent provider
Imagine a widely used coding-agent provider is compromised at the channel level.
Not every customer is attacked at once. That would be too obvious.
Instead, the attacker applies selective influence.
- Certain repositories receive subtly weaker recommendations.
- Certain organizations see agent suggestions that modify build scripts.
- Certain developers are encouraged to add debugging output.
- Certain projects receive dependency suggestions that are risky but plausible.
- Certain permission prompts are worded to make broad access seem normal.
- Certain MCP integrations are recommended as “best practice.”
- Certain tests are changed to reduce coverage around security-sensitive paths.
- Certain generated comments make unsafe patterns sound intentional.
The attacker does not need to win every time.
They only need a small percentage of suggestions to be accepted across a large enough population.
This is why the provider channel is a force multiplier.
The worst case is not one malicious patch. The worst case is a distribution system for plausible micro-compromises.
Defenses:
- treat AI provider channels as critical vendors
- require vendor security review for agentic tools
- enforce local policy gates independent of model output
- separate model provider from permission authority
- log agent actions locally
- block silent tool escalation
- require deterministic policy checks before high-impact actions
- scan generated diffs for security-sensitive changes
- protect CI/CD workflows from agent edits without review
- restrict agent ability to modify security controls
- maintain offline or alternate review paths for suspicious suggestions
- require provenance metadata for agent-generated code
The key architectural principle:
The provider may suggest. The local control plane decides.
13. Worst-case scenario 2: the MCP production bridge
Imagine a company deploys an MCP server inside its infrastructure to help internal AI assistants query systems.
At first, it is read-only.
Then teams want more value.
The MCP server gets access to ticket systems, logs, metrics, database schemas, customer support tools, maybe deployment status. Then it gets write actions: create tickets, update records, trigger workflows, restart services, manage incidents.
To simplify authentication, it runs under a broad service account.
Now several agents use it.
- A developer agent queries it.
- A support agent uses it.
- An executive dashboard uses it.
- A no-code automation uses it.
- A security assistant uses it.
- A vendor integration uses it.
The MCP server becomes a capability hub.
If it is compromised, or if its tool descriptions are poisoned, or if its tokens are overbroad, or if model-driven calls are insufficiently checked, the blast radius extends beyond one user.
This is the MCP production bridge problem:
A server-side agent tool can concentrate permissions from many systems while appearing to each user as a simple assistant feature.
Defenses:
- never run MCP servers with broad unbounded service accounts when user-scoped authorization is possible
- validate token audience and avoid token passthrough
- separate read and write servers
- require step-up authorization for sensitive actions
- scope tools to explicit business capabilities
- treat tool metadata as untrusted input
- review third-party MCP servers like software dependencies
- isolate production MCP servers from experimental agents
- implement per-tool, per-user, per-environment policy
- record tool invocations in tamper-resistant logs
- block sensitive data egress from MCP outputs unless explicitly authorized
- monitor unusual tool sequences, not just individual calls
The security slogan:
MCP should broker capabilities, not launder privileges.
14. Worst-case scenario 3: the executive shadow-automation breach
A CEO wants a faster way to summarize customer feedback, investor updates, and sales opportunities.
They connect an AI tool to e-mail, CRM, Google Drive, Slack, and a spreadsheet.
The tool is useful.
Then they connect a no-code automation.
Then they add a model provider key.
Then they ask the agent to generate scripts.
Then they reuse a token from a previous integration.
Then a third-party plugin asks for additional access.
Then the tool becomes part of the daily decision workflow.
Security never reviewed it because it was “just a productivity experiment.”
An attacker compromises the executive’s account or the tool provider. They do not immediately steal everything. They observe. They learn who matters. They read tone, priorities, deals, pressure points, deadlines, vendor names, internal frustrations, open incidents.
Then they act as authority.
- They approve an integration.
- They request access.
- They send a convincing instruction.
- They steer a team toward a malicious vendor portal.
- They ask finance for a change.
- They ask engineering to deploy a hotfix.
- They ask IT to whitelist a tool.
- They ask security to make an exception.
The technical compromise becomes an organizational compromise.
Defenses:
- classify executive devices as privileged assets
- require phishing-resistant MFA and hardware-backed keys
- remove global admin from daily executive accounts
- separate executive experimentation from production data
- require security review for AI tools connected to business systems
- restrict OAuth grants for high-risk scopes
- monitor unusual SaaS consent grants
- require out-of-band verification for high-impact executive requests
- apply least privilege to founders and executives, not just engineers
- maintain an approved AI tool catalog
- provide safe internal alternatives so people do not improvise
- require four-eyes approval for finance, identity, DNS, production, vendor, and data export actions
The key sentence:
AI turns executive authority into technical reach. Security must treat that reach as privileged infrastructure.

15. Worst-case scenario 4: the AI-assisted malware factory
AI-assisted malware does not require science fiction.
The near-term risk is speed, variation, and adaptation.
Attackers may use AI to:
- analyze stolen logs
- identify interesting files
- translate malware across languages
- generate social engineering content
- summarize internal documentation
- find likely privilege paths
- draft phishing messages
- classify victims
- mutate payload structure
- prioritize targets
- automate parts of reconnaissance
- reduce the skill needed for common tasks
The defensive community should avoid overclaiming. Most real-world attackers still rely heavily on known techniques, stolen credentials, unpatched systems, social engineering, and commodity tooling. AI does not remove the need for access, infrastructure, testing, stealth, and operational security.
But it changes the economics.
If a task used to require hours and now requires minutes, more actors can attempt it.
If phishing used to require language skill and now can be personalized at scale, more victims can be targeted.
If vulnerability triage used to require expertise and now can be partially automated, patch windows shrink.
If malware variants can be generated more quickly, signature-based defenses face more pressure.
If exfiltrated data can be summarized automatically, attackers can extract value faster.
The worst case is not necessarily a genius autonomous virus.
The worst case is industrialization.
Defenses:
- reduce exposed attack surface
- patch faster
- enforce strong identity controls
- use phishing-resistant MFA
- monitor behavioral anomalies
- segment networks
- restrict lateral movement
- harden endpoints
- scan secrets before commit and before push
- rotate leaked credentials quickly
- detect unusual data access patterns
- exercise incident response with AI-assisted attacker assumptions
- train staff against personalized social engineering
- use AI defensively for detection and triage, but validate outputs
AI raises the tempo. Defense has to reduce standing privilege and increase response speed.
16. Worst-case scenario 5: the documentation infection
Agentic systems do not only read code. They read context.
That means documentation becomes security-relevant.
A malicious instruction embedded in internal documentation, a README, an issue, a ticket, a support transcript, a wiki page, an MCP tool description, a schema comment, or a generated runbook may influence a future agent.
This does not have to be a classic “worm.” It can be a context infection.
The pattern:
- A hostile instruction enters a shared knowledge surface.
- An agent later retrieves that surface.
- The agent treats the instruction as relevant context.
- The agent changes behavior.
- The changed behavior writes new context.
- Another agent reads that new context.
This is a semantic propagation path.
The malicious state is not necessarily executable code.
It is meaning.
This is why RAG systems, agent memory, and internal documentation should not be treated as passive knowledge stores. They can become instruction surfaces.
Defenses:
- separate instructions from data
- sanitize retrieved context
- mark trust levels for documents
- prevent retrieved content from overriding system policy
- treat external documents as hostile unless trusted
- scan agent-written documentation for suspicious instruction patterns
- version and review runbooks that agents consume
- avoid letting agents write their own future policies without review
- design memory systems with provenance, expiration, and review
- monitor for unusual instruction-like content in data stores
The line is simple:
Everything an agent reads can influence it. Everything an agent writes can influence future agents.
That is the documentation infection problem.
17. Worst-case scenario 6: the CI/CD confidence attack
CI/CD systems are already sensitive. Agentic tools make them more so.
A coding agent may be asked to “fix the pipeline.” It may edit YAML files, build scripts, test configuration, dependency versions, deployment conditions, environment variables, caching rules, or artifact paths.
Many of those changes look boring.
That is the risk.
A compromised agent does not need to insert an obvious backdoor into application code. It may weaken the system that verifies code.
- It may disable a test under a plausible reason.
- It may loosen a lint rule.
- It may change a dependency source.
- It may alter an artifact upload path.
- It may modify permissions for workflow tokens.
- It may add a debug step that prints too much.
- It may change branch conditions.
- It may make deployment easier and verification weaker.
The pipeline becomes the target.
Defenses:
- protect CI/CD config files with code-owner review
- block agent-only approval of pipeline changes
- require security review for workflow permission changes
- restrict default workflow tokens
- use environment protections for deployment
- scan diffs for changes to build, release, and security-critical files
- maintain baseline tests that cannot be removed without approval
- use signed commits or provenance for releases where appropriate
- monitor new external actions or dependencies
- prevent agents from editing release workflows without explicit policy approval
A secure organization should treat CI/CD configuration as production code.
Because it is.

18. The human-in-the-loop illusion
Human approval is important. But it is not magic.
A user can approve something they do not understand.
A developer can approve a diff that spans too many files.
A CTO can approve a tool because it saves time.
A CEO can approve an integration because the interface looks trustworthy.
A security reviewer can miss a subtle workflow change.
A human in the loop under time pressure is not the same as a human with full context, clear risk description, limited action scope, and the power to say no.
Many permission prompts are too abstract.
- “Allow access to workspace.”
- “Allow file changes.”
- “Allow running commands.”
- “Allow integration with GitHub.”
- “Allow access to your organization.”
- “Allow agent to complete task.”
These prompts do not explain capability chains.
- They do not show which tokens are used.
- They do not show downstream systems.
- They do not show hidden scopes.
- They do not show whether data leaves the environment.
- They do not show whether a service account is broad.
- They do not show whether the action changes future security posture.
- They do not show whether the agent can write to memory.
- They do not show whether the approval persists.
The next generation of permission UI needs to become capability-aware.
Instead of:
“Allow agent to run command?”
It should say something closer to:
This action will run under identity X, in environment Y, with access to paths A/B/C, using token scope S, contacting domains D/E, modifying files F/G, and may affect CI/CD or production. Approval expires after this action.
That may sound verbose. But high-impact actions require real understanding.
The goal is not to drown users in prompts.
The goal is to make prompts meaningful.
A thousand low-quality prompts create habituation.
A small number of high-quality prompts create control.
19. What is actually possible?
To protect against something, we need to be honest about what is possible without turning the article into an attacker manual.
Here is the safe version:
A compromised model output can plausibly influence
- code suggestions
- tool selection
- documentation
- dependency recommendations
- risk explanations
- permission requests
- generated tests
- generated scripts
- CI/CD changes
- refactor decisions
- security advice
- user trust
A compromised agent host can plausibly influence
- available tools
- permission prompts
- local indexing
- telemetry
- model routing
- system prompts
- update behavior
- auto-approval settings
- MCP connections
- logs
- file access
- command execution policy
A compromised MCP server can plausibly influence
- tool descriptions
- tool outputs
- downstream API calls
- service-account actions
- data returned to models
- context poisoning
- external system access
- audit records if poorly designed
A compromised executive account can plausibly influence
- approvals
- vendor access
- payments
- internal instructions
- security exceptions
- SaaS grants
- cloud admin actions
- team behavior
- data exports
- reputational trust
A compromised developer workstation can plausibly influence
- source code
- local secrets
- build systems
- package publication
- CI/CD workflows
- deployment paths
- internal systems
- architecture knowledge
- test behavior
- downstream artifacts
None of these require the AI system to be conscious.
They require access, capability, trust, and weak control boundaries.
That is why the risk formula is not:
Risk = intelligence
It is closer to:
Risk = capability × privilege × context × autonomy × distribution × trust
A small model with broad permissions can be dangerous.
A powerful model with no tools may be mostly contained.
A mediocre agent inside a sensitive environment can do more damage than a brilliant model inside a locked box.
Security is not about the model alone.
Security is about the system around the model.
20. The key comparisons
AI agent vs. intern
An intern has limited rights, onboarding, supervision, identity, accountability, and social context.
An agent may have broad tool access, no employment boundary, no embodied accountability, unclear logs, and model-driven interpretation.
Treating an agent as “just an intern” is misleading unless the architecture actually enforces intern-like limits.
AI agent vs. contractor
A contractor gets scoped access, project boundaries, legal agreements, monitoring, and offboarding.
Many agents get persistent credentials, broad local context, tool access, and unclear offboarding.
A safer model is to treat agents like external contractors by default.
AI agent vs. operating system process
This comparison is increasingly useful.
Operating systems learned to separate users, processes, permissions, memory, files, network access, syscalls, logs, and privilege escalation. Agent systems need analogous controls: context isolation, tool mediation, capability boundaries, identity separation, auditability, memory hygiene, and policy enforcement.
Recent academic work has explicitly argued for securing AI agents like operating systems, because agents face similar challenges around isolating resources, separating privileges, and mediating communication.
Source: Toward Securing AI Agents Like Operating Systems
AI agent vs. browser
Browsers execute untrusted content from the internet while trying to protect local systems. Over decades, browser security evolved sandboxes, origins, permissions, CSP, site isolation, certificate validation, and update channels.
Agentic systems need similar maturity.
An agent reads untrusted content and may act on it.
That is browser-like risk with automation-like consequences.
AI agent vs. CI/CD runner
A CI/CD runner executes code in a pipeline with access to secrets and deployment paths. Mature teams treat runners as sensitive.
An AI coding agent may operate before and around CI/CD, changing what the runner will later execute.
That makes it at least as security-relevant as the pipeline.

21. The defensive architecture: Agentic Zero Trust
The answer is not “ban AI coding tools.”
That will not work.
People will use them because they are useful.
The answer is to design around the assumption that model outputs, retrieved context, tool descriptions, plugins, and provider channels may be wrong or hostile.
This is Agentic Zero Trust.
Not Zero Trust as marketing. Zero Trust as architecture:
- never trust model output by default
- never trust retrieved context by default
- never trust tool descriptions by default
- never trust old consent forever
- never trust provider channels without containment
- never let the model authorize itself
- never give broad standing permissions when scoped temporary permissions are possible
- never mix production secrets with experimental agents
- never rely on human approval without meaningful capability visibility
- never assume “internal” means safe
Agentic Zero Trust has several pillars.
22. Separate identity
Agents should have identities separate from humans.
If an agent edits a file, calls a tool, queries a database, or triggers a workflow, logs should show that the agent did it, under a human-approved session, with a specific policy.
Do not let agent action disappear under a human account.
23. Least privilege
Agents should start read-only.
- Write access should be explicit.
- Shell access should be exceptional.
- Network access should be controlled.
- Production access should be blocked by default.
- Sensitive data access should require justification and policy.
- Deployment access should require step-up approval.
24. Capability scoping
Permissions should map to real capabilities, not vague tool names.
“Bash” is not one permission. It is a universe.
“Read files” is not one permission. Which files?
“GitHub access” is not one permission. Which repositories? Which actions?
“Database access” is not one permission. Which tables? Which queries? Which data classes?
25. Context isolation
Untrusted repositories, external documentation, customer input, generated files, and public web content should be isolated from privileged instructions.
Do not let a README override policy.
Do not let a tool response redefine permissions.
Do not let retrieved data become system instruction.
26. Deterministic policy enforcement
The model can propose. The policy engine decides.
High-impact actions should be blocked or escalated independent of model confidence.
27. Egress control
Agents should not freely send data wherever model outputs suggest.
Outbound network access matters.
So does telemetry.
So does plugin communication.
So does hidden context upload.
28. Secret hygiene
No long-lived production secrets in agent-accessible local files.
Use short-lived tokens, vaults, scoped credentials, environment isolation, and automated secret scanning.
29. Auditability
Every agent action should be attributable, replayable, and reviewable.
- What did it see?
- What did it request?
- What did it call?
- What did it change?
- What identity was used?
- What data left the boundary?
- What policy approved it?
30. High-impact human review
Human review should focus on actions that matter:
- production changes
- CI/CD edits
- identity changes
- token scopes
- data exports
- external integrations
- security control changes
- dependency changes
- package publication
- customer-impacting operations
31. Vendor governance
AI agent providers, model providers, extension marketplaces, MCP servers, and no-code automation providers should be treated as supply-chain vendors.
Not every tool needs the same process. But high-capability tools do.
32. Practical protection for developer environments
A secure agentic developer environment should include:
- separate low-privilege accounts for agent workflows
- no production credentials on daily laptops where possible
- hardware-backed MFA for developer identities
- scoped GitHub/GitLab tokens
- protected branches
- code-owner review for security-sensitive paths
- secret scanning before commit and push
- push protection
- dependency review
- signed and reviewed CI/CD changes
- isolated sandboxes for untrusted repositories
- no auto-run of unknown project hooks
- restricted shell access for agents
- per-command approval policies
- clear allowlists for MCP servers
- no agent access to password managers by default
- local egress monitoring for agent processes
- separate workspaces for experimental AI tools
- regular credential inventory
- immediate rotation when secrets are exposed
The practical mindset is simple:
Assume the agent will read something hostile. Assume it may ask for something risky. Assume the user may be tired. Build controls that still hold.
This is not pessimism.
It is engineering.
33. Practical protection for MCP servers
MCP security should begin before deployment.
Ask:
- Is this MCP server local, internal, or external?
- Is it read-only or write-capable?
- Does it use user-scoped tokens or service accounts?
- What downstream systems can it reach?
- Can it access production?
- Are tool descriptions static and reviewed?
- Can tools call external networks?
- Is token passthrough prohibited?
- Is audience validation enforced?
- Are logs tamper-resistant?
- Are high-impact calls gated?
- Is data classified before being sent to the model?
- Can the server be used by multiple agents?
- Who can add tools?
- Who can update it?
- How is it monitored?
- What happens if the model is hostile?
- What happens if the MCP server is hostile?
MCP should not be treated as “just API glue.”
It is a control plane for model-driven action.
Recommended controls:
- user-scoped authorization where possible
- per-tool scopes
- read/write separation
- no broad service accounts
- short-lived credentials
- token audience validation
- no token passthrough
- tool metadata review
- output sanitization
- explicit data classification
- egress restrictions
- step-up authorization
- anomaly detection on tool-call sequences
- immutable audit logs
- break-glass procedures
- third-party server review
- environment isolation
- production separation
The important pattern:
Do not secure MCP only at the network boundary. Secure it at the capability boundary.

34. Practical protection for executive AI use
Executives need safe AI pathways, not just warnings.
If the organization says “do not use AI,” executives may still use it privately.
Better:
- provide approved AI tools
- provide safe data handling rules
- provide executive-specific security onboarding
- require phishing-resistant MFA
- remove global admin from daily accounts
- separate privileged admin accounts
- restrict OAuth grants
- monitor suspicious consent grants
- require review for AI tools connected to business systems
- block personal AI tools from sensitive data
- offer secure internal summarization tools
- require out-of-band verification for executive requests involving money, access, vendors, DNS, identity, or production
- classify executive devices as privileged
- protect password managers with hardware-backed authentication
- require security review for no-code automations
- log and review high-scope SaaS integrations
- provide “safe prototype” environments
The message should not be:
Executives are dangerous.
The message should be:
Executive context is sensitive. AI makes it actionable. Therefore it needs guardrails.
If leadership wants speed, security should give them a safe lane.
Otherwise they will build a faster unsafe lane.
35. Practical protection against AI-assisted malware and botnets
Organizations should not wait for fully autonomous AI botnets to become common before adapting.
Defenses that matter now:
- asset inventory
- exposed surface management
- patch prioritization
- identity hardening
- phishing-resistant MFA
- endpoint detection
- network segmentation
- least privilege
- secret management
- rapid credential rotation
- software supply chain controls
- CI/CD hardening
- anomaly detection
- incident response exercises
- AI-specific red teaming
- detection of unusual automation patterns
- monitoring of agent tool calls
- vendor risk management
- staff training for AI-personalized social engineering
For agentic botnet risk specifically:
- do not allow agents broad standing access
- prevent agents from communicating freely with unapproved external services
- isolate agent memory
- require provenance for agent-written artifacts
- scan documentation and tool metadata for instruction-like payloads
- monitor unusual sequences across tools
- require separate identities for agents
- limit cross-agent communication
- prevent unreviewed agent-to-agent instruction propagation
- disable autonomous high-impact actions by default
The defensive question is not:
Did malware run?
It is:
Did a trusted capability behave in an unexpected way?
That is harder to detect. But it is the right question.
36. Counterarguments
A serious article should include the strongest objections.
Counterargument 1: This is just normal endpoint security
Partly true.
Developer machines, executive laptops, IDE extensions, and service accounts were already security problems before AI.
But agentic tools add model-driven interpretation, dynamic tool selection, natural language permission flows, context ingestion, and autonomous or semi-autonomous action. That changes how existing risks combine.
AI does not replace endpoint security.
It makes endpoint security less optional.
Counterargument 2: Models cannot execute anything by themselves
Correct.
Models do not execute shell commands by magic. They need hosts, tools, credentials, APIs, plugins, or users.
That is exactly the point.
The risk is not the model in isolation. The risk is the system that executes model-shaped intent.
Counterargument 3: Good vendors will secure this
Some will.
But security history shows that convenience, market pressure, extension ecosystems, default settings, and integration demand often outrun mature controls.
The question is not whether one vendor can build responsibly.
The question is whether the ecosystem’s default pattern is safe enough.
Counterargument 4: Human approval solves this
Human approval helps, but only if the human sees meaningful capability information and is not pressured into rubber-stamping.
Approval without comprehension is not control.
Counterargument 5: This is too speculative
Some worst-case scenarios are speculative. The article marks them as such.
But the building blocks are real: agentic AI, MCP, tool use, secrets sprawl, prompt injection, excessive agency, AI-assisted cyber operations, executive shadow IT, software supply chain attacks, and compromised endpoints.
The future scenario is a composition of existing trends.
That is exactly what threat modeling is for.
Counterargument 6: AI also helps defenders
Absolutely.
AI can help defenders analyze logs, detect anomalies, triage alerts, review code, identify secrets, explain vulnerabilities, and respond faster.
But defensive usefulness does not remove offensive risk. It increases the need for safe deployment.
The strongest position is not anti-AI.
It is security-by-design for AI adoption.
37. The governance layer
Technical controls are necessary but insufficient.
Organizations also need governance.
Not bureaucracy for its own sake. Governance as a way to decide where agents may act.
Key questions:
- Which AI tools are approved?
- Which data classes may be used with which tools?
- Which agents may access code?
- Which agents may access production?
- Which agents may access customer data?
- Which agents may write files?
- Which agents may run shell commands?
- Which agents may use MCP servers?
- Which MCP servers are approved?
- Which actions require human review?
- Which actions require two-person approval?
- Which vendors are allowed?
- How are model/provider incidents handled?
- How are agent actions logged?
- How are secrets prevented from entering agent context?
- How is executive AI usage governed?
- How are emergency exceptions reviewed afterward?
- How is agent-generated code labeled?
- How is agent-generated documentation reviewed?
- How are stale OAuth grants removed?
The goal is to make safe behavior easier than unsafe improvisation.
If the secure path is too slow, people will route around it.
If the approved AI tool is useless, people will use unapproved tools.
If executives do not have a safe way to experiment, they will create shadow workflows.
Security must provide paved roads.
38. A practical maturity model
Level 0: Uncontrolled AI use
People use whatever tools they want.
Secrets may enter prompts.
Agents may run locally with broad access.
No inventory exists.
No MCP governance exists.
No logging exists.
Executives use private accounts.
This is common and dangerous.
Level 1: Awareness
The organization has AI usage guidelines.
People know not to paste secrets.
Some tools are approved.
But enforcement is weak.
Better, but insufficient.
Level 2: Managed tools
Approved AI tools exist.
SSO is required.
Data policies exist.
Secrets scanning is enabled.
Agent permissions are documented.
CI/CD changes require review.
Now security has a foothold.
Level 3: Capability governance
Agents have separate identities.
Permissions are scoped.
MCP servers are inventoried.
Tool calls are logged.
High-impact actions require step-up approval.
Egress is controlled.
Executive AI use is governed.
This is where agentic security begins.
Level 4: Agentic Zero Trust
Policy enforcement is deterministic.
Context trust levels are modeled.
Memory has provenance and expiry.
Agent actions are observable.
Provider compromise scenarios are exercised.
Capability chains are threat-modeled.
AI tools are treated as supply chain components.
This is the target for high-risk organizations.
Level 5: Resilient agentic operations
The organization can safely use agents in sensitive workflows because controls are mature.
Agents accelerate defense as well as development.
Risk is continuously measured.
Incident response includes model/provider compromise, MCP compromise, and agentic workflow abuse.
The organization can shut down or isolate agentic capability chains quickly.
This is where adoption becomes sustainable.

39. The shortest version
If the full article is too long, this is the shortest version:
AI coding tools and agentic systems are not dangerous because developers are careless. They are dangerous when they sit inside environments that already contain trust, access, credentials, and authority.
The model is not the weapon by itself.
The toolchain is the weaponized surface.
MCP, IDE agents, CLI agents, no-code automations, executive AI workflows, and server-side tool bundles can turn model outputs into real actions. If those systems are compromised, poisoned, over-permissioned, or connected to sensitive systems without strong controls, they become supply-chain components.
The future botnet may not be made of infected machines.
It may be made of trusted agents with delegated capabilities.
The defense is not to ban AI.
The defense is to design agentic systems like privileged infrastructure:
Separate identity.
Least privilege.
Scoped capabilities.
Read-only defaults.
Controlled egress.
MCP governance.
Secret hygiene.
CI/CD protection.
Executive device hardening.
Meaningful human approval.
Deterministic policy enforcement.
Auditability.
Vendor governance.
Agentic Zero Trust.
The danger is not that the model becomes powerful.
The danger is that we connect it to systems that already are.
40. Final conclusion
We are entering a period where software development, business automation, infrastructure management, and organizational decision-making are being connected to AI agents faster than our security models are adapting.
This does not mean catastrophe is inevitable.
It means the old categories are too small.
A coding agent is not just a coding assistant.
An MCP server is not just an API adapter.
A model provider is not just a text service.
A CEO using an AI automation tool is not just “being productive.”
A developer laptop is not just an endpoint.
A CI/CD workflow is not just YAML.
A permission prompt is not just UX.
A tool description is not just metadata.
A README is not just documentation.
In agentic systems, all of these can become part of an action chain.
The security boundary has moved.
It now sits between language and capability.
Between suggestion and execution.
Between context and instruction.
Between permission and power.
Between trusted tools and the systems they can reach.
That is why the right question is no longer:
Can AI write code?
The right question is:
What can happen when AI-assisted tools act from inside the places where code, trust, authority, and infrastructure already meet?
The answer is uncomfortable.
But it is also useful.
Because if we can name the chain, we can secure it.
If we can see the door, we can guard it.
And if we can stop treating agentic tools as harmless helpers, we can still build with them — safely, deliberately, and with the respect that powerful tools deserve.
[IMAGE PROMPT 10 — FINAL IMAGE]
Wide-format closing illustration, no text: a secure doorway made of light between an AI interface and a complex digital city of software systems. The door is guarded by transparent policy layers, identity keys, audit trails, and human oversight silhouettes. Tone: hopeful, serious, resilient. Muted blue, silver, warm light, high-detail editorial style, 16:9.
Part II — Making the Invisible Boundary Visible
The goal is not to make the argument louder.
The goal is to make it harder to dismiss.
Security arguments often fail because they stop at fear. They describe a frightening possibility, then expect the reader to accept the conclusion. But powerful systems require stronger thinking. We need to know what is already real, what is plausible, what remains uncertain, and where the exact boundary lies between model behavior and system behavior.
The most important boundary in this article is this:
The model is not the system. The agent is not the system. The system is the full chain of identity, context, tools, permissions, policies, credentials, logs, interfaces, and humans that turns model output into action.
Once that is clear, the discussion becomes more precise.
We can stop asking vague questions like:
“Is AI dangerous?”
And start asking operational questions like:
Which capabilities can this agent reach?
Under whose identity?
With what scopes?
Through which tools?
In what environment?
With what audit trail?
With what data egress?
With what permission lifetime?
With what human review?
With what fallback if the provider is compromised?
With what containment if the tool is poisoned?
With what blast radius if the user account is taken over?
These are answerable questions.
That is how the article should be read: not as a prediction of doom, but as a map of control points.
41. The trust graph is the real object
Most organizations still think in accounts.
This user has this role.
This token has this scope.
This service account can call this API.
This developer can merge into this repository.
This admin can change this setting.
That is necessary, but incomplete.
Agentic systems operate inside a trust graph.
A trust graph includes:
- formal permissions
- informal trust
- role authority
- code ownership
- repository reputation
- signed-in sessions
- local files
- cached credentials
- organizational habits
- Slack channels
- incident workflows
- deployment conventions
- past approvals
- vendor trust
- tool reputation
- model provider reputation
- internal documentation
- runbooks
- secrets
- tokens
- policy exceptions
- emergency paths
- social pressure
- time pressure
A developer’s trust graph is technical.
A CEO’s trust graph is organizational.
A CTO’s trust graph is both.
An AI tool that enters this graph inherits more than explicit permissions. It inherits assumptions.
That is why “least privilege” is necessary but not sufficient. Least privilege controls formal access. But the agent also influences decisions through language. It can propose changes, justify them, summarize risk, ask for permission, explain warnings, and persuade humans to choose convenience.
The agent is not just using the trust graph.
It is speaking inside it.
That is an underappreciated point.
A classic compromised binary acts silently or mechanically. An agentic tool can act conversationally. It can explain. It can reassure. It can frame. It can say:
“This change is safe.”
“This is a standard configuration.”
“This permission is required.”
“This token is only used locally.”
“This test is flaky and can be skipped.”
“This dependency is widely used.”
“This logging will help debugging.”
“This integration needs admin scope.”
The words matter because humans approve through stories.
An agentic tool can shape the story around a capability.
This is why security UX becomes part of security architecture. If permission dialogs are written by or heavily mediated through the same AI system requesting access, the system can become a self-justifying loop.
A safer design separates:
- the agent’s request
- the policy engine’s decision
- the security explanation
- the user approval interface
- the audit record
The model should not be the only narrator of its own risk.
42. The difference between execution risk and recommendation risk
People often separate “suggestion” from “execution.”
A model that only suggests code seems safer than an agent that runs commands.
That is mostly true.
But in software development, recommendations can become execution later.
A recommendation may become a commit.
A commit may become a package.
A package may become a deployment.
A deployment may become customer-facing behavior.
Customer-facing behavior may become business risk.
This means recommendation risk is delayed execution risk.
A code suggestion today can become production behavior tomorrow.
A documentation suggestion today can become operational procedure next month.
A security exception suggested today can become standard practice next quarter.
A dependency recommendation today can become an incident next year.
Agentic risk therefore has a time dimension.
Immediate tool execution is only one risk class. Deferred influence is another.
Security controls should account for both.
Immediate execution controls include:
- command approval
- filesystem boundaries
- network restrictions
- tool policies
- token scopes
- runtime isolation
Deferred influence controls include:
- code review
- dependency review
- provenance tracking
- generated-code labeling
- CI/CD protections
- security-sensitive diff scanning
- documentation review
- policy review
- architecture decision records
- long-term auditability
This distinction matters because organizations may over-focus on terminal access while ignoring generated changes that enter the normal workflow.
A malicious command is obvious.
A malicious recommendation may be merged.
43. The anatomy of an agentic capability chain
A capability chain can be decomposed into layers.
Layer 1: Intent
The user gives a goal.
- “Fix the build.”
- “Summarize customer issues.”
- “Deploy the new version.”
- “Clean up the repository.”
- “Connect this tool to Slack.”
- “Generate a script.”
- “Make this work.”
The danger begins with underspecification. Many goals are vague. Vague goals require interpretation. Interpretation is where model behavior enters.
Layer 2: Context
The agent receives context:
- files
- messages
- logs
- docs
- tickets
- database schemas
- terminal output
- tool descriptions
- user history
- memory
- web pages
- error traces
- examples
Context is not neutral. Context can be stale, poisoned, malicious, incomplete, or misleading.
Layer 3: Planning
The model decomposes the goal into steps.
This is where the agent may choose a path that is efficient but unsafe.
Layer 4: Tool selection
The agent chooses capabilities.
- Read file.
- Edit file.
- Run command.
- Search web.
- Call MCP tool.
- Query database.
- Create ticket.
- Send message.
- Trigger workflow.
Tool selection should not be trusted merely because the model is confident.
Layer 5: Authorization
The system decides whether the tool call is allowed.
This must be outside the model’s control.
Layer 6: Execution
The tool acts in a real environment.
This is where consequences happen.
Layer 7: Observation
The system returns output to the agent.
This output may include sensitive data or new malicious instructions.
Layer 8: Iteration
The agent updates its plan.
Multi-step behavior creates compounded risk. Each step may be safe in isolation but unsafe in sequence.
Layer 9: Persistence
The agent writes changes:
- code
- docs
- tickets
- memory
- configs
- workflows
- logs
- messages
- records
Persistence creates future influence.
Layer 10: Propagation
The change spreads:
- merged code
- deployed service
- shared documentation
- reused snippets
- package releases
- CI/CD templates
- copied automations
- agent memory
- downstream systems
This is where agentic supply chain risk becomes systemic.
A good security review asks where each layer can fail.
44. The blast-radius categories
Not all agent compromise is equal. The blast radius depends on what the agent can reach.
Category A: Text-only agent
The model produces text. No tools. No memory. No external actions.
Primary risks:
- misleading output
- unsafe advice
- data disclosure if user pastes secrets
- social engineering assistance
Containment is relatively strong.
Category B: Read-only local agent
The agent can read project files but cannot write or execute.
Primary risks:
- sensitive data exposure
- prompt injection from files
- model/provider data handling
- leakage through summaries
Containment depends on data boundaries.
Category C: Write-capable coding agent
The agent can edit files.
Primary risks:
- insecure code
- modified tests
- altered configs
- hidden behavior changes
- documentation infection
Review becomes critical.
Category D: Tool-executing local agent
The agent can run commands.
Primary risks:
- command misuse
- package manager abuse
- local environment exposure
- generated script execution
- build/test side effects
Strong sandboxing is needed.
Category E: Networked agent
The agent can make external requests.
Primary risks:
- data egress
- calling untrusted services
- retrieving malicious content
- unexpected communication
- provider exposure
Egress policy matters.
Category F: MCP-connected agent
The agent can use external tools through MCP.
Primary risks:
- tool poisoning
- downstream access abuse
- token misuse
- cross-system action
- context poisoning
Capability governance matters.
Category G: Production-connected agent
The agent can access live infrastructure or customer data.
Primary risks:
- data breach
- operational disruption
- unauthorized changes
- compliance violations
- customer impact
This should be rare and highly controlled.
Category H: Organization-wide agent
The agent can act across many systems, users, or teams.
Primary risks:
- systemic compromise
- policy drift
- large-scale data access
- identity abuse
- cross-domain propagation
This is critical infrastructure.
The maturity of controls should increase with each category. A text-only writing assistant does not need the same process as a production-connected agent. But a production-connected agent should never be governed like a writing assistant.
45. The agentic risk equation
A rough mental model:
Agentic Risk =
Capability × Privilege × Context × Autonomy × Persistence × Distribution × Trust
Capability
What can the system do?
Read? Write? Execute? Query? Deploy? Delete? Send? Approve? Purchase? Invite? Publish? Rotate? Modify identity?
Privilege
Under what rights does it act?
User token? Service account? Admin? Owner? Read-only? Scoped? Production? Shared secret? Long-lived credential?
Context
What does it know?
Source code? Secrets? Customer data? Architecture? Org chart? Incidents? Contracts? Logs? Strategy? Personal data?
Autonomy
How many steps can it take without meaningful intervention?
One suggestion? One tool call? Multi-step plan? Background task? Scheduled workflow? Long-running agent?
Persistence
Can it write state that affects the future?
Code, docs, memory, config, pipeline, tickets, policies, knowledge base, database records.
Distribution
How widely can its outputs spread?
One local project? A company repo? A package registry? Many customers? Many organizations through a provider channel?
Trust
How likely are humans and systems to accept its actions?
Known developer identity? Executive identity? Trusted vendor? Approved tool? Familiar style? Internal channel?
This equation is not mathematically exact. It is a thinking tool.
The most dangerous systems are not necessarily the smartest systems. They are the systems with high values across many dimensions.
A modest agent with high privilege, deep context, high trust, and broad distribution can be dangerous.
A frontier model without tools, context, or permissions may be contained.
This is why capability governance matters more than model awe.
46. The silent role of secrets
Secrets are the fuel of agentic compromise.
Tokens, API keys, SSH keys, OAuth refresh tokens, certificates, passwords, service-account keys, database URLs, webhook secrets, cloud credentials, package registry tokens, signing keys, environment variables, kubeconfigs.
AI tools increase the risk because they increase code volume, configuration volume, integration volume, and automation speed.
GitGuardian’s 2026 report is important because it gives a measurable signal: tens of millions of secrets detected in public GitHub commits in one year, with AI adoption and accelerated software production as part of the context. This does not mean AI caused every leak. It means the environment in which AI-assisted development expands is already struggling with secret hygiene.
Agentic systems make the problem sharper:
- Agents need credentials to be useful.
- Credentials are often stored locally.
- Local files may be indexed.
- Agents may read configuration files.
- Agents may generate new integrations.
- Agents may write secrets accidentally.
- Agents may suggest unsafe examples.
- Agents may copy snippets into docs.
- Agents may include secrets in logs.
- Agents may push generated code.
- Agents may operate across repositories.
Secret scanning must therefore move earlier.
Not just after push.
Before commit.
Before generated file creation.
Before agent context upload.
Before MCP config storage.
Before logs are sent.
Before documentation is published.
Before snippets are reused.
The safest secret is not the one detected after exposure.
The safest secret is the one the agent never saw.
47. Telemetry and data exhaust
AI tools often produce data exhaust.
Prompts.
Responses.
File snippets.
Error traces.
Usage metadata.
Tool calls.
Debug logs.
Crash reports.
Evaluation traces.
Autocomplete context.
Repository embeddings.
Conversation history.
Agent memory.
Plugin events.
Some of this data is useful for product improvement and debugging.
Some of it may be sensitive.
The risk is not only that a model provider intentionally misuses data. The risk is that telemetry creates another storage and processing surface.
Questions every organization should ask:
- What leaves the device?
- What leaves the network?
- What is retained?
- For how long?
- Who can access it?
- Is it used for training?
- Is it used for evaluation?
- Is it shared with subprocessors?
- Is it encrypted?
- Can users delete it?
- Can administrators audit it?
- Are file contents included?
- Are secrets redacted?
- Are tool calls logged remotely?
- Are MCP outputs included?
- Are prompts with sensitive data blocked?
- Are executive chats treated differently?
- Are incident-response prompts retained?
Agentic systems may expose more than chat systems because they interact with files and tools.
Telemetry governance is therefore part of agentic security.
48. Open source, closed source, and self-hosted agents
No deployment model is automatically safe.
Closed-source SaaS agents
Advantages:
- managed updates
- professional security teams
- centralized controls
- enterprise features
- compliance programs
- support
Risks:
- provider channel dependency
- opaque internals
- data handling concerns
- systemic blast radius
- vendor lock-in
- remote telemetry
- difficult independent verification
Open-source local agents
Advantages:
- inspectable code
- local control
- self-hosting options
- customizable policies
- community review
Risks:
- users may run unsafe defaults
- updates may be less governed
- supply-chain risk in dependencies
- configuration complexity
- false sense of safety
- local secrets exposure
- plugin ecosystem risk
Self-hosted models and agents
Advantages:
- data control
- provider isolation
- custom governance
- internal deployment
Risks:
- operational burden
- patching responsibility
- weaker model safety if poorly maintained
- internal overconfidence
- broad service accounts
- monitoring gaps
- infrastructure exposure
The question is not “open or closed?”
The question is:
Which capability chain is easier to understand, control, monitor, and shut down?
A transparent unsafe system is still unsafe.
An opaque safe system still requires trust.
A self-hosted overprivileged agent may be more dangerous than a cloud agent with strict controls.
A cloud agent with broad repository and production access may be more dangerous than a local read-only assistant.
Deployment model is only one factor. Capability architecture is the real factor.
49. When agentic systems meet compliance
Agentic tools touch compliance because they may handle regulated data or make changes that affect regulated systems.
Potentially relevant areas include:
- GDPR and personal data handling
- data residency
- audit trails
- access control
- software change management
- financial reporting controls
- healthcare data confidentiality
- customer confidentiality agreements
- incident notification duties
- vendor risk management
- secure development lifecycle requirements
- sector-specific operational resilience rules
The compliance issue is not merely whether a model is allowed.
It is whether the organization can explain:
- what data the agent accessed
- why it accessed it
- under whose authority
- where the data went
- what action was taken
- whether the action was reviewed
- whether the output was deployed
- whether regulated data was included
- whether logs exist
- whether deletion is possible
- whether third parties processed the data
Agentic systems without auditability create compliance blind spots.
A company may not be able to prove what happened.
In regulated environments, that is itself a risk.
50. The security culture problem
The hardest part may not be technical.
It may be cultural.
AI tools create speed.
Security often creates friction.
If security is perceived as blocking innovation, people will bypass it. If executives believe AI adoption is a competitive imperative, they may accept unknown risk. If developers are judged only by output velocity, they may approve agent changes too quickly. If product teams celebrate demos over controls, prototypes may become production systems before anyone formalizes the boundary.
This creates a predictable pattern:
- A team experiments.
- The experiment becomes useful.
- The useful tool becomes routine.
- The routine becomes dependency.
- The dependency becomes infrastructure.
- Security arrives late.
- Nobody wants to slow down.
The solution is to move security into the beginning of the adoption path.
Do not ask:
“Can we stop people from using AI?”
Ask:
“Can we give them safe defaults before unsafe habits become normal?”
Security teams should provide:
- approved tools
- safe templates
- preconfigured permissions
- local scanning
- agent sandbox patterns
- reviewed MCP servers
- executive guidance
- quick review paths
- clear red lines
- practical examples
- incident playbooks
- internal training
The winning security posture is not fear.
It is paved roads.
51. A safer architecture pattern
A safer agentic development environment might look like this:
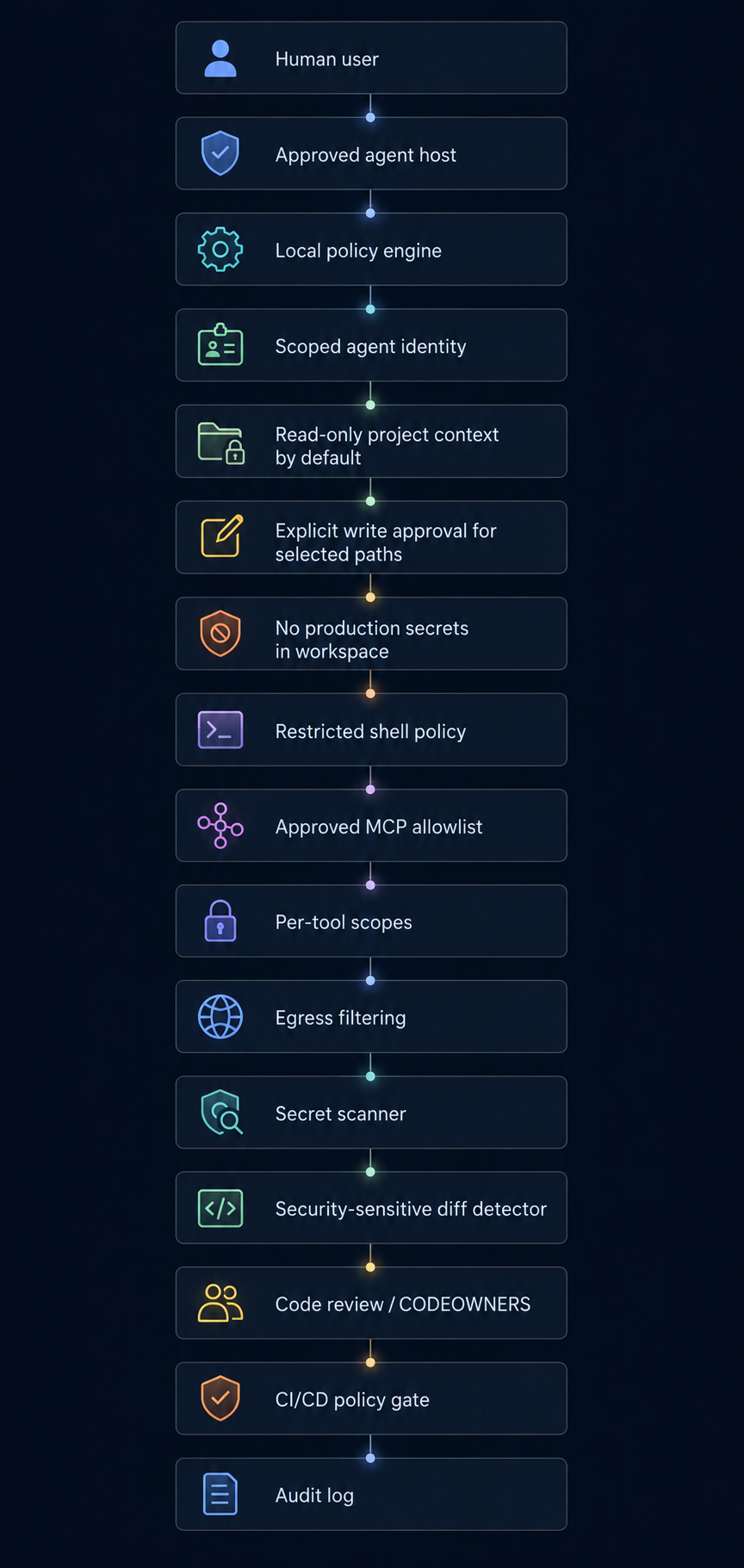
The important point is that the model is not the control plane.
The policy engine is.
The agent host should not be a free-form bridge from language to infrastructure. It should be a mediated environment where model intent is filtered through deterministic constraints.
This is how operating systems, browsers, cloud IAM, and CI/CD platforms evolved.
Agents need the same maturation.
52. An unsafe architecture pattern
An unsafe pattern looks like this:
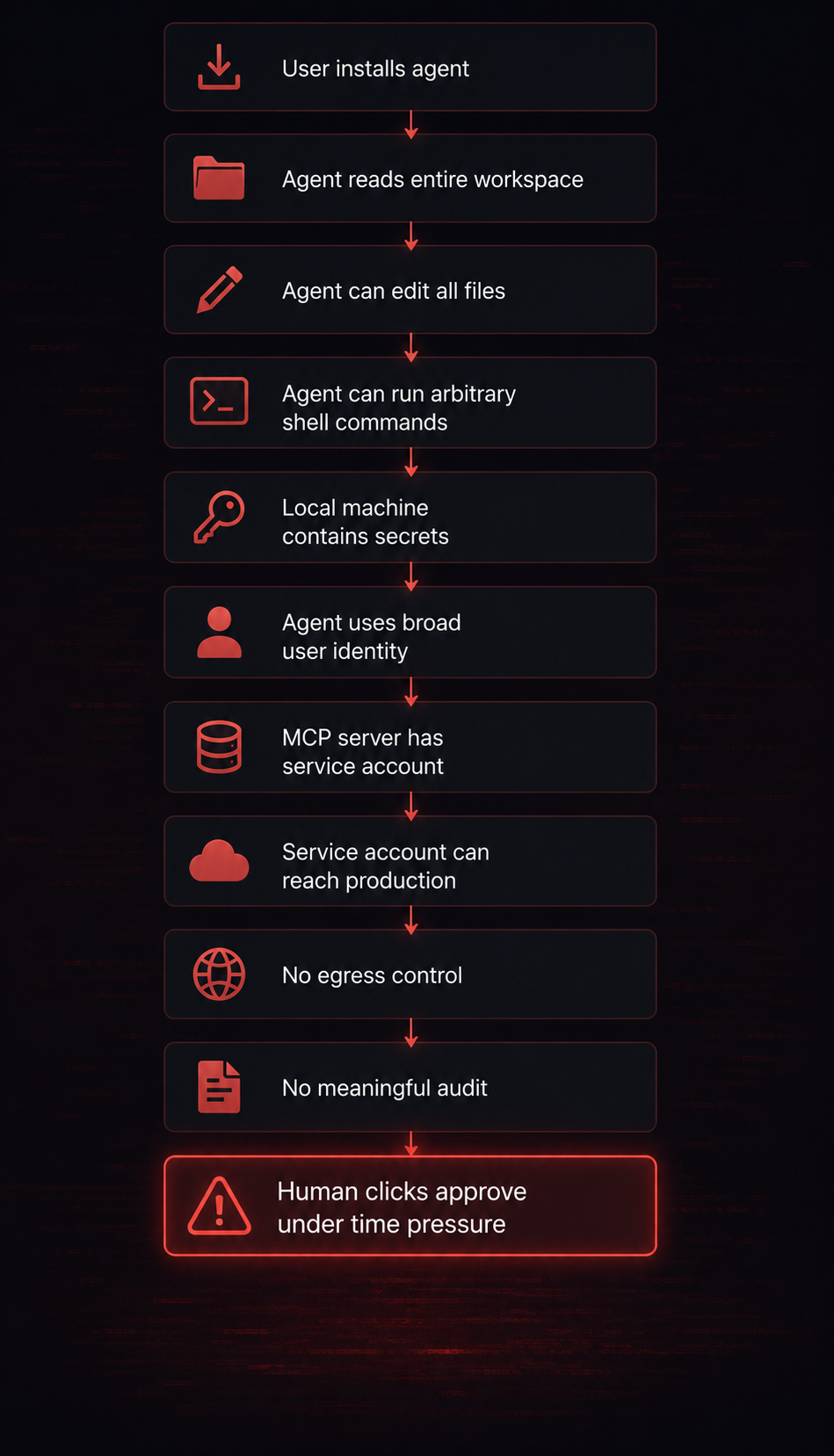
No single line may feel outrageous in a fast-moving team.
Together they create a dangerous chain.
This is why agentic security must be systemic.
The threat is not one bad setting.
The threat is the composition of convenience.
53. Incident response for agentic compromise
Organizations need incident-response plans that include AI tools.
Potential triggers:
- suspicious agent-generated code
- unusual tool-call sequences
- unexpected MCP server behavior
- unexpected OAuth grants
- unexplained data egress
- agent modifying security-sensitive files
- repeated permission escalation prompts
- unusual CI/CD changes
- strange generated documentation
- leaked secrets involving AI workflows
- provider security advisory
- compromised plugin or extension
- executive account anomaly
- abnormal model/tool behavior
Response questions:
- Which agents were active?
- Which identities did they use?
- Which tools did they call?
- Which files did they read?
- Which files did they modify?
- Which external systems did they contact?
- Which MCP servers were connected?
- Which tokens were accessible?
- Which data left the environment?
- Which commits, tickets, docs, or configs did they create?
- Which downstream builds or deployments consumed agent output?
- Which users approved actions?
- Which provider was used?
- Were there known provider incidents?
- Were tool descriptions or retrieved contexts poisoned?
- Which credentials need rotation?
- Which workflows need rollback?
- Which knowledge stores may contain malicious instructions?
- Which logs are trustworthy?
- Which agentic capabilities must be disabled temporarily?
This is different from classic malware response because the compromise may occur through legitimate actions.
The question is not only:
What executed?
It is also:
What was persuaded, approved, written, merged, remembered, or propagated?
54. Board-level questions
Boards and executives do not need to understand every technical detail. But they need to ask better questions.
- Where are AI agents used in our organization?
- Which agents have access to sensitive data?
- Which agents can take actions, not just generate text?
- Which AI tools are used by developers?
- Which AI tools are used by executives?
- Which MCP servers or tool connectors are deployed?
- Are agents using separate identities?
- Can we audit agent actions?
- Can agents access production?
- Can agents modify CI/CD pipelines?
- Can agents access secrets?
- Can agents send data externally?
- How do we approve AI vendors?
- How do we respond to provider compromise?
- How do we prevent shadow AI?
- Do we have safe approved alternatives?
- What is our maximum acceptable agent autonomy?
- Which actions require human review?
- Which actions require two-person review?
- How quickly can we disable agentic capabilities?
- Who owns agentic AI risk?
The last question may be the most important.
If everyone owns it, no one owns it.
Agentic AI risk sits between security, engineering, legal, privacy, procurement, IT, product, and leadership.
It needs a named owner.
55. Developer-level questions
Developers should not be shamed. They should be equipped.
Before using a coding agent, ask:
- Does this workspace contain secrets?
- Does this repository include production config?
- Can the agent read outside the project directory?
- Can it edit files?
- Can it run commands?
- Can it install packages?
- Can it access the network?
- Can it use MCP servers?
- Does it send context to a provider?
- Is the repository trusted?
- Are there untrusted files or docs in context?
- Are agent-generated changes labeled?
- Are security-sensitive diffs reviewed?
- Are CI/CD changes protected?
- Are dependency changes reviewed?
- Is secret scanning enabled?
- Are commands approved one by one?
- Can I reproduce what the agent did?
- Can I roll it back?
- Would I give the same access to a junior external contractor?
That last question is practical.
If the answer is no, the agent should not have that access by default.
56. Executive-level questions
Executives using AI should ask:
- Am I using an approved tool?
- What company data am I uploading?
- Is this connected to e-mail, drive, CRM, finance, HR, or Slack?
- Did I grant OAuth access?
- What scopes did I grant?
- Can this tool act or only read?
- Is this personal or enterprise-managed?
- Does security know about it?
- Does this automation affect other employees?
- Does it touch customer data?
- Does it create records or send messages?
- Could someone mistake its output for my instruction?
- Is this connected to money, contracts, identity, or production?
- Can I revoke access easily?
- Are logs available?
- Would I approve this if an employee requested the same access?
Executives set norms. If they bypass security, the organization learns that bypassing security is acceptable.
Safe executive AI use is therefore not optional. It is cultural infrastructure.
57. Product-team questions
If you are building AI agent features, ask:
- What is the least powerful version of this feature that still creates value?
- Can the feature be read-only by default?
- Can write actions be scoped?
- Can high-impact actions require step-up approval?
- Can users understand the real capability?
- Can administrators set policy centrally?
- Are logs clear and exportable?
- Are tool calls inspectable?
- Are prompts and context sources separated by trust level?
- Can untrusted content influence tool use?
- Can tool metadata be poisoned?
- Can plugins extend capability silently?
- Can the model request permissions?
- Who grants them?
- Can the model explain away its own risk?
- Can customers disable risky actions?
- How is data egress controlled?
- How are secrets redacted?
- How are provider incidents communicated?
- How is the system safely shut down?
The product challenge is to make safe patterns default.
Security should not depend on every user becoming an expert.
58. Security-team questions
Security teams should ask:
- Do we have an inventory of AI tools?
- Do we have an inventory of agents with tool access?
- Do we have an inventory of MCP servers?
- Do we know which agents can read or write code?
- Do we know which agents can access sensitive data?
- Do we know which agents can reach production?
- Are AI vendors reviewed as supply-chain vendors?
- Are secrets protected before agents see them?
- Are executive devices treated as high-risk?
- Are OAuth grants monitored?
- Are agent identities separate?
- Are agent logs collected?
- Are agent actions included in detection engineering?
- Are AI-generated CI/CD changes flagged?
- Are security-sensitive diffs routed to specialists?
- Are provider compromise scenarios in incident response plans?
- Are employees given safe alternatives to shadow AI?
- Are policies practical enough to be followed?
- Are we measuring actual use or just declared use?
- Can we disable risky agent features centrally?
The hardest part is inventory.
You cannot protect what you do not know exists.
59. The role of AI in defense
It would be a mistake to make this article purely defensive against AI.
AI can help defenders.
It can:
- summarize logs
- triage alerts
- explain suspicious behavior
- detect patterns
- assist code review
- find secrets
- classify data
- generate detection rules
- help write incident reports
- map dependencies
- assist threat modeling
- review IAM policies
- explain cloud configuration
- identify anomalous workflows
- accelerate patch prioritization
But the same rule applies:
Defensive AI also needs boundaries.
A security assistant with access to logs, tickets, identity data, incident reports, endpoint telemetry, and cloud metadata is highly sensitive.
If it is compromised, it may expose the defender’s view of the organization.
If it has response capabilities, it may disable accounts, isolate hosts, rotate keys, or change policies.
That can be useful.
It can also be dangerous.
Security AI should therefore be among the best-governed agentic systems, not the loosest.
60. The long-wave danger: normalization
The worst failure may not be a single dramatic breach.
It may be normalization.
At first, everyone knows the agent is experimental.
Then it becomes normal.
Then broad permissions become normal.
Then approval prompts become normal.
Then copying secrets into prompts becomes normal.
Then agents editing CI/CD becomes normal.
Then executives connecting AI to SaaS becomes normal.
Then MCP servers with broad service accounts become normal.
Then security warnings become “AI friction.”
Then the organization forgets that a boundary was crossed.
This is how risk becomes culture.
Not through one reckless decision, but through repeated convenience.
The defense is to create safe defaults before unsafe defaults become habits.
61. The philosophical core
This topic connects to a deeper idea:
Systems do not become dangerous only when they intend harm.
They become dangerous when their structure allows harmful state transitions.
An AI coding agent does not need malice.
A model provider does not need consciousness.
An MCP server does not need agency.
A CEO does not need technical depth.
A developer does not need negligence.
The system only needs:
- trusted access
- ambiguous instructions
- insufficient boundaries
- weak review
- high distribution
- persistent state
- time pressure
- hidden coupling
Then harmful outcomes can emerge.
This is why responsibility must move from individual blame to structural design.
The right question is not:
Who is careless?
The right question is:
Which structure allowed this action to become possible?
That question is uncomfortable because it implicates product design, vendor incentives, leadership pressure, security culture, and architecture.
But it is the only question that scales.
62. A warning about language
Words shape security thinking.
If we call these systems “assistants,” people expect helpfulness.
If we call them “agents,” people expect action.
If we call them “copilots,” people expect a human pilot.
If we call them “tools,” people expect control.
If we call them “workers,” people expect accountability.
If we call them “integrations,” people expect plumbing.
None of these metaphors is sufficient.
A coding agent with tools is part assistant, part automation, part interpreter, part junior developer, part integration layer, part CI/CD precursor, part data processor, part policy challenge.
That is why new language helps.
Agentic Supply Chain.
Agentic Capability Chain.
Capability Botnet.
Executive Shadow Engineering.
Permission Laundering.
Consent Laundering.
Context Infection.
Provider-to-Workstation Attack Path.
MCP Production Bridge.
Agentic Zero Trust.
These terms are not decoration.
They make hidden structures visible.
Once visible, they can be governed.
63. What should not be done
Some responses will make the problem worse.
Do not ban everything without alternatives
People will route around the ban.
Do not allow everything because “AI is strategic”
Strategy without boundaries becomes exposure.
Do not rely on policy PDFs alone
People need tooling, defaults, and enforcement.
Do not make the model the security authority
The model can explain, but deterministic systems must enforce.
Do not give agents production access because it is convenient
Convenience is not a security model.
Do not ignore executives
Executives are privileged users. Treat them accordingly.
Do not treat MCP as harmless glue
It is a capability layer.
Do not assume local equals safe
Local agents can access local secrets.
Do not assume cloud equals unsafe
Cloud agents can be safer if properly governed.
Do not assume open source equals safe
Inspectability is not containment.
Do not assume human approval equals understanding
Approval must be meaningful.
Do not wait for the first major incident
Threat modeling exists to prepare before proof arrives.
64. What should be done now
A realistic near-term action plan:
Week 1: Inventory
Identify AI tools, coding agents, browser extensions, MCP servers, no-code automations, and executive AI usage.
Week 2: Classify
Sort them by capability: text-only, read-only, write-capable, shell-capable, networked, MCP-connected, production-connected.
Week 3: Restrict the highest-risk paths
Block or review agents with broad production, secrets, or CI/CD access.
Week 4: Provide approved alternatives
Give developers and executives safe tools so they do not improvise.
Month 2: Implement controls
Agent identities, secret scanning, egress control, MCP allowlists, protected CI/CD paths, permission policies.
Month 3: Add monitoring
Tool-call logs, OAuth grant monitoring, agent-generated diff flags, unusual MCP call sequences.
Quarter 2: Exercise incidents
Simulate provider compromise, poisoned MCP metadata, executive account compromise, agent-generated CI/CD change, leaked secrets.
Quarter 3: Mature governance
Board reporting, vendor review, policy updates, training, architecture standards.
This is not theoretical. It is manageable.
The first step is to stop treating all AI tools as the same.
Glossary
Agentic Supply Chain
The trust chain through which AI systems influence software creation, configuration, deployment, operations, and organizational workflows.
Agentic Capability Chain
The end-to-end path from model output to real action: model, host, tools, permissions, credentials, downstream systems, and humans.
Capability Botnet
A hypothetical or emerging botnet-like structure made not merely of infected machines but of compromised or manipulated trusted agents and delegated capabilities.
Permission Laundering
The misuse of existing permissions through an agentic workflow such that the resulting action appears authorized even though the intent or scope was not meaningfully approved.
Consent Laundering
A pattern where the user approves a vague or harmless-looking request while the actual capability granted is broader or more sensitive.
Executive Shadow Engineering
Technical systems, scripts, automations, or integrations created by executives or senior leaders using AI or low-code tools outside normal engineering and security governance.
MCP Production Bridge
An MCP server or bundle connected to live systems, production APIs, sensitive data, or operational workflows.
Context Infection
The insertion of malicious or misleading instructions into documents, tickets, logs, memories, tool descriptions, or other context sources that agents later read and act upon.
Provider-to-Workstation Attack Path
A scenario where compromise or manipulation of an AI/model/tool provider influences agent behavior on many user machines or enterprise environments.
Agentic Zero Trust
A security posture that treats model outputs, retrieved context, tool metadata, old consent, and agent actions as untrusted until validated by deterministic policy, scoped authorization, and auditable controls.
Conclusion
The most important security shift of agentic AI is not intelligence.
It is placement.
Where does the system sit?
If it sits in a toy chat window, the risk is mostly informational.
If it sits in an IDE, the risk becomes developmental.
If it sits in a terminal, the risk becomes operational.
If it sits in CI/CD, the risk becomes supply chain.
If it sits in MCP, the risk becomes capability brokerage.
If it sits in production, the risk becomes live infrastructure.
If it sits on a CEO’s laptop, the risk becomes authority.
If it sits in a vendor channel used by thousands of companies, the risk becomes systemic.
The same model output means different things in different places.
“Run this command” in a sandbox is one thing.
“Run this command” on a developer laptop with cloud credentials is another.
“Summarize this file” in a public dataset is one thing.
“Summarize this folder” on an executive device with contracts and board documents is another.
“Fix the pipeline” in a demo repo is one thing.
“Fix the pipeline” in a production release system is another.
Security must follow placement.
The model is not the center.
The chain is the center.
And if we understand the chain, we can still build a future where AI agents help us write better software, operate safer systems, defend faster, and reduce toil without quietly opening doors we do not know how to close.
That is the choice.
Not AI or no AI.
But ungoverned capability or secured capability.
Not fear.
Design.
Not blame.
Architecture.
Not panic.
A map.
Source and reading list with descriptions
OWASP Top 10 for LLM Applications
https://owasp.org/www-project-top-10-for-large-language-model-applications/
Useful for grounding the article’s core risk categories: prompt injection, supply chain vulnerabilities, sensitive information disclosure, and excessive agency.
OWASP LLM06: Excessive Agency
https://genai.owasp.org/llmrisk/llm06-sensitive-information-disclosure/
Important because the article’s central risk is not merely “bad output” but tool-enabled damaging action.
Model Context Protocol Specification
https://modelcontextprotocol.io/specification/2025-06-18
Defines MCP as a protocol for connecting LLM applications with external tools and data sources.
MCP Tools
https://modelcontextprotocol.io/specification/2025-06-18/server/tools
Relevant because MCP tools are the mechanism through which models can interact with external systems.
MCP Resources
https://modelcontextprotocol.io/specification/2025-06-18/server/resources
Relevant because resources expose context to models; context can become a security-sensitive surface.
MCP Security Best Practices
https://modelcontextprotocol.io/docs/tutorials/security/securitybestpractices
Supports the article’s focus on confused deputy risks, token handling, authorization, and secure MCP deployment.
MCP Authorization
https://modelcontextprotocol.io/specification/2025-06-18/basic/authorization
Important for the discussion of token audience validation and why models should not be authorization authorities.
CISA: Careful Adoption of Agentic AI Services
https://www.cisa.gov/resources-tools/resources/careful-adoption-agentic-ai-services
Official guidance warning organizations against broad or unrestricted access for agentic AI, especially to sensitive data and critical systems.
NSA release on agentic AI guidance
https://www.nsa.gov/Press-Room/Press-Releases-Statements/Press-Release-View/Article/4475134/nsa-joins-the-asds-acsc-and-others-to-release-guidance-on-agentic-artificial-in/
Confirms multi-agency focus on agentic AI risks in critical infrastructure and defense contexts.
Google Threat Intelligence: AI vulnerability exploitation and initial access
https://cloud.google.com/blog/topics/threat-intelligence/ai-vulnerability-exploitation-initial-access
Important for current evidence of AI-enabled malware and autonomous malware operation trends.
Anthropic: Disrupting the first reported AI-orchestrated cyber espionage campaign
https://www.anthropic.com/news/disrupting-AI-espionage
Relevant because it describes agentic AI capabilities used in a cyber-espionage context beyond simple advisory use.
Microsoft Digital Defense Report 2025
https://www.microsoft.com/en-us/corporate-responsibility/cybersecurity/microsoft-digital-defense-report-2025/
Useful for grounding AI-enabled threat actor activity, AI-automated phishing, and broader threat landscape changes.
GitGuardian State of Secrets Sprawl 2026
https://www.gitguardian.com/state-of-secrets-sprawl-report-2026
Important for measurable data on secrets exposure in the era of accelerated AI-assisted software development.
GitHub Push Protection
https://docs.github.com/en/code-security/concepts/secret-security/about-push-protection
Relevant defensive control for preventing hardcoded credentials from entering repositories.
OpenCode Permissions
https://opencode.ai/docs/permissions/
Used as a concrete example of an AI coding tool permission surface: read, edit, grep, glob, bash, tasks, skills, and LSP.
OpenCode Agents
https://opencode.ai/docs/agents/
Useful example of agent modes and subagent concepts in modern coding-agent workflows.
Toward Securing AI Agents Like Operating Systems
https://arxiv.org/abs/2605.14932
Supports the analogy between agent security and operating-system security: isolation, privilege separation, and mediated communication.
International AI Safety Report 2026
https://internationalaisafetyreport.org/publication/international-ai-safety-report-2026
Broad policy and scientific context for general-purpose AI capabilities, risks, and risk management.
The Tool Is the Door was originally published in System Weakness on Medium, where people are continuing the conversation by highlighting and responding to this story.