In Post 7, we covered the full spectrum of RAG architectures, from Naive RAG to CRAG, Adaptive, Agentic, and GraphRAG. You now know when to use which architecture and why.
But here's the uncomfortable question nobody wants to ask after building all of this: how do you know if any of it is actually working?
Think about it. Your RAG system answers questions. Sometimes the answers look great. Sometimes they're... questionable. You shipped it to production because the vibes felt right.
That's not a strategy. That's a prayer.
You're basically running a factory with zero quality control hoping the final product slaps, but you have no measurements at any stage, no idea which part of the pipeline is broken when things fail, no way to know if your "improvements" actually improved anything, and no systematic way to catch problems before your users do.
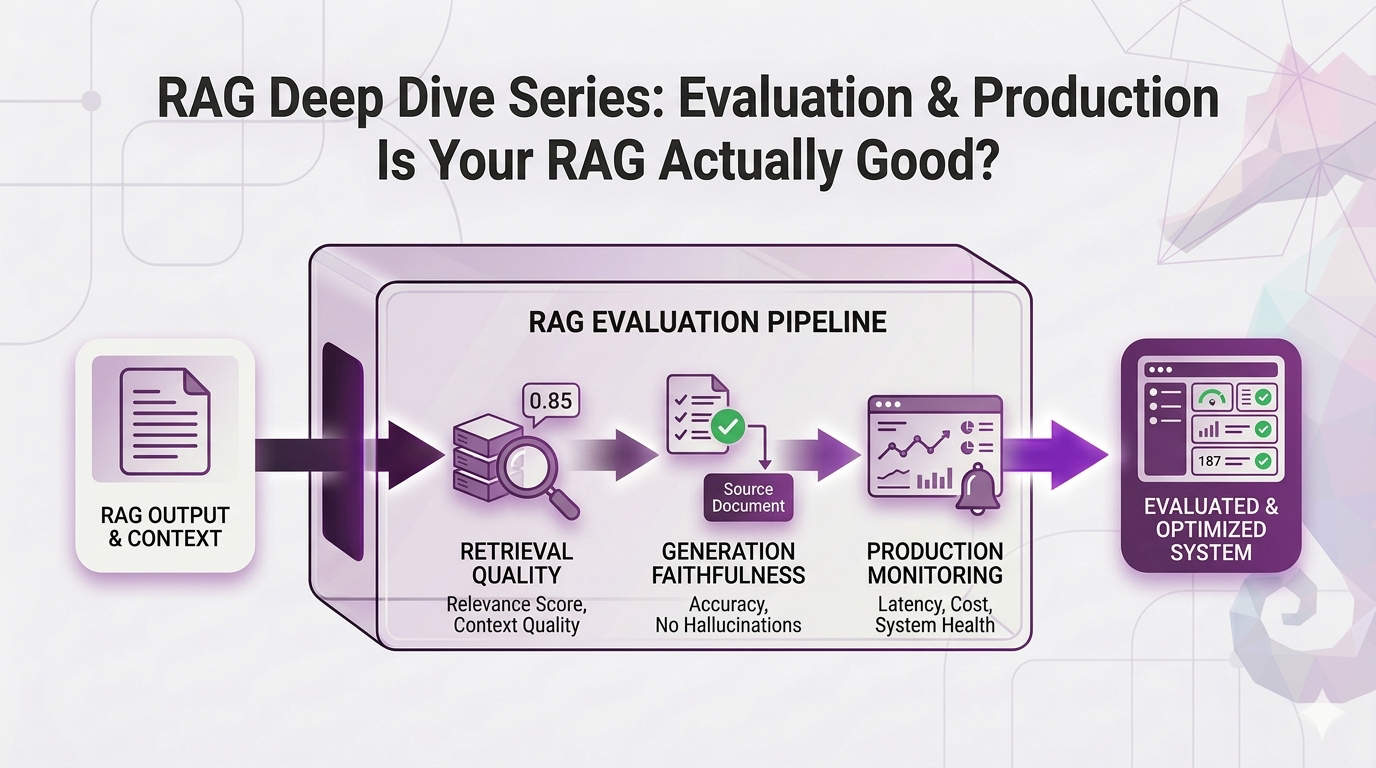
This post is about fixing that. We're going from "it seems to work" to "here's exactly how well it works, here's what's broken, and here's how we're going to keep it running."
No code. No jargon without context. Just the metrics, the testing strategies, and the production monitoring that separates a demo from a real system.
Let's close this series out.
Table of Contents
- The Two-Stage Assembly Line
- Stage 1: Is Retrieval Doing Its Job?
- Stage 2: Is the LLM Doing Its Job?
- Building Your Eval Dataset: The Ground Truth Problem
- A/B Testing: The Scientific Method for RAG
- Production Monitoring: Quality Control That Never Stops
- Your Evaluation Roadmap
- Key Takeaways
- The Full Journey: Series Wrap-Up
The Two-Stage Assembly Line
Before we can measure quality, we need to internalize something: your RAG system isn't one thing. It's a two-stage assembly line.
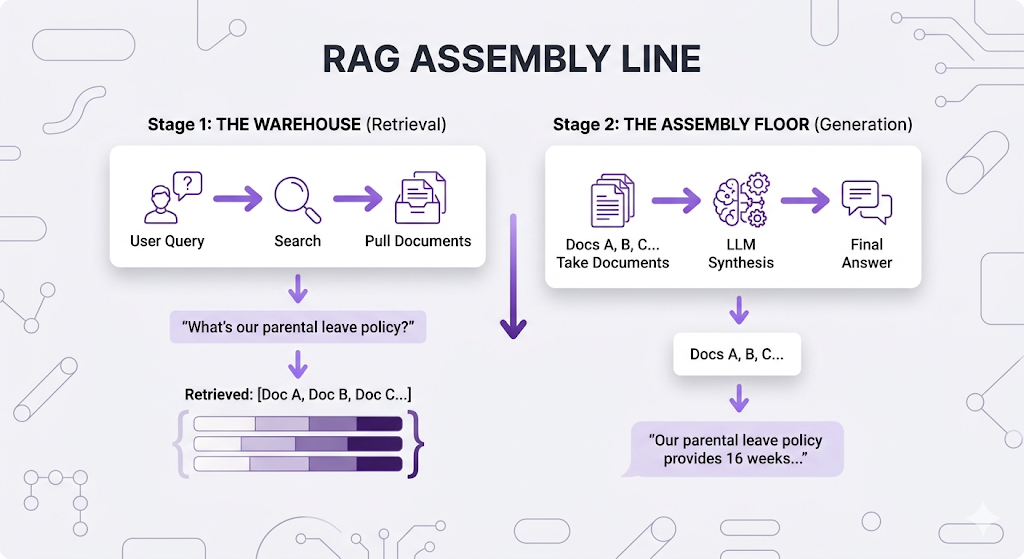
Critical insight: these stages can fail independently.
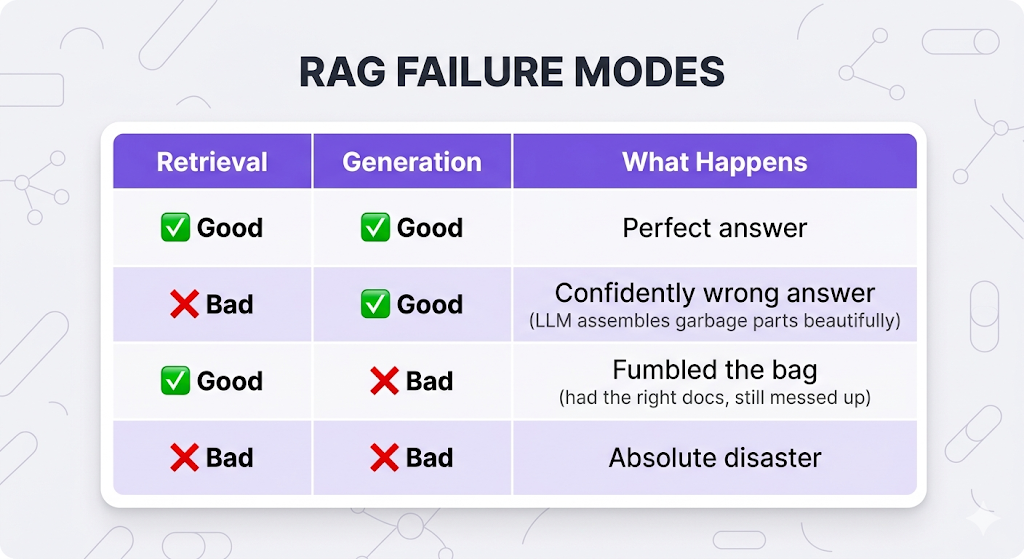
This is why evaluation is hard. When a user gets a wrong answer, you can't just say "the system failed." You need to know where it failed. Was the warehouse pulling the wrong parts? Or did the assembly floor fumble with perfectly good parts?
You need quality checks at BOTH stages. Let's build them.
Stage 1: Is Retrieval Doing Its Job?
The warehouse (retrieval) has one job: grab the documents that actually answer the user's question.
But "grab the right documents" isn't one metric it's actually measuring several different failure modes. And each failure mode has its own metric. Let's walk through them.
Failure Mode 1: Missing Critical Documents
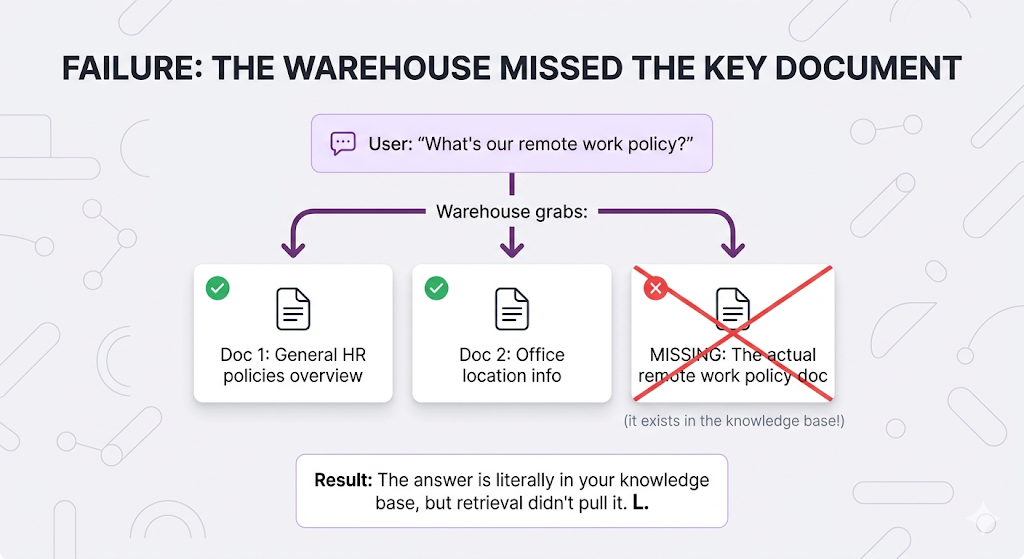
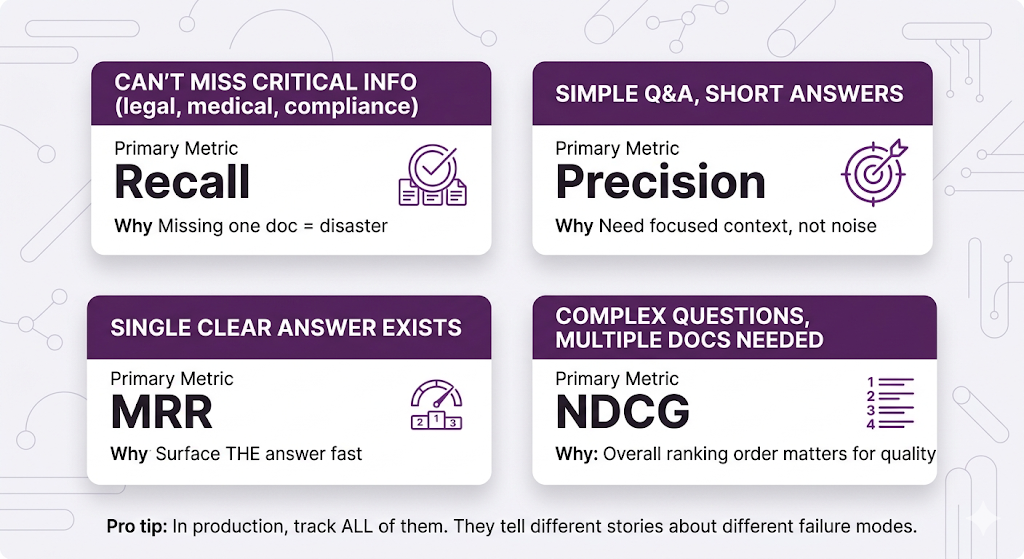
The metric for this is Recall of all the relevant documents that exist, what percentage did you actually grab?
Recall = (Relevant docs retrieved) / (Total relevant docs that exist)
Perfect recall (1.0) = You found ALL the relevant documents
Terrible recall (0.3) = You only found 30% of what you should have
When low recall kills you: Anything where missing information is dangerous compliance, legal, medical. If your HR bot misses the parental leave policy because retrieval skipped it, someone's making a major life decision with incomplete info. Not great.
Failure Mode 2: Grabbing Too Much Junk
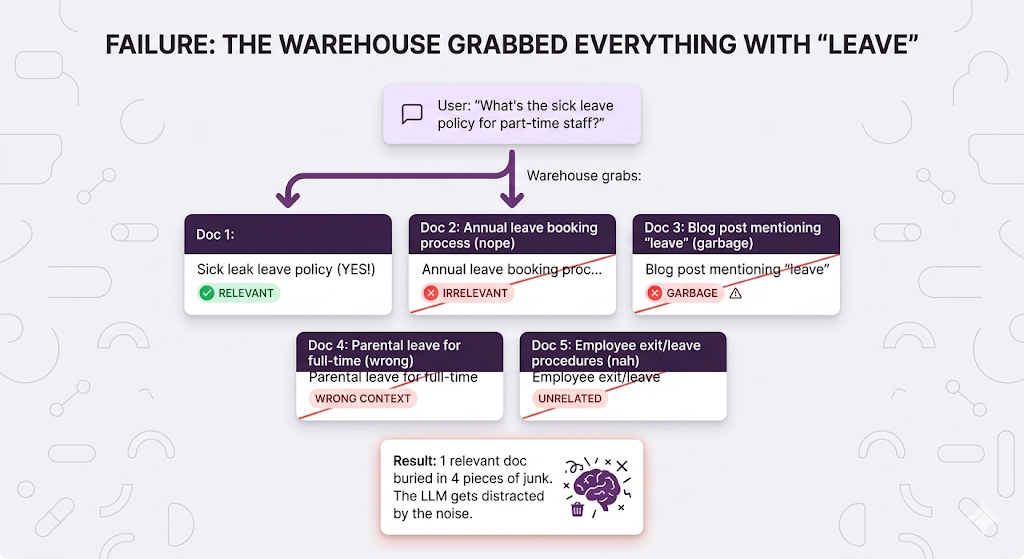
The metric for this is Precision of all the documents you grabbed, what percentage were actually relevant?
Precision = (Relevant docs retrieved) / (Total docs retrieved)
Perfect precision (1.0) = Every doc you grabbed was relevant
Terrible precision (0.2) = 80% of what you grabbed was junk
When low precision kills you: Simple Q&A bots, customer support the LLM gets confused by irrelevant context and starts weaving in random information from the junk docs. Your user asks about sick leave and gets a paragraph about parental leave mixed in. Mid.
The Precision-Recall Tug of War
Here's where it gets spicy: these two metrics fight each other.

The balance depends on your use case:
- Legal research? Bias toward recall, can't miss anything critical.
- Simple FAQ bot? Bias toward precision, keep the context focused.
- Most real systems? Find the sweet spot in the middle and tune from there.
Failure Mode 3: Ranking Is Trash
Sometimes you grab the right documents... but you buried them.
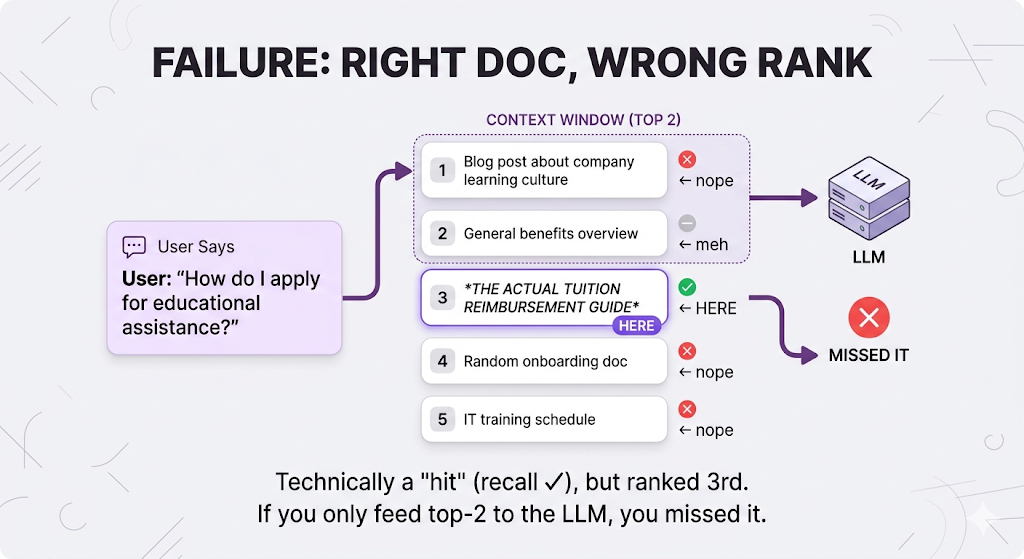
The metric for this is Mean Reciprocal Rank (MRR) how quickly do you surface the first relevant document?
MRR = Average of (1 / rank of first relevant doc)
First relevant doc at rank 1: 1/1 = 1.0 (perfect)
First relevant doc at rank 3: 1/3 = 0.33 (kinda mid)
First relevant doc at rank 10: 1/10 = 0.1 (yikes)
Why this matters: LLMs have context limits. If the right doc is ranked 50th, it might not even make it into the context window. And even when it does, LLMs tend to pay more attention to content at the beginning and end of their context stuff in the middle gets ignored. So ranking isn't just about finding the doc. It's about putting it where the LLM will actually use it.
Failure Mode 4: Overall Ranking Is Sus
MRR only cares about the first relevant document. But what if multiple documents matter and their order matters?
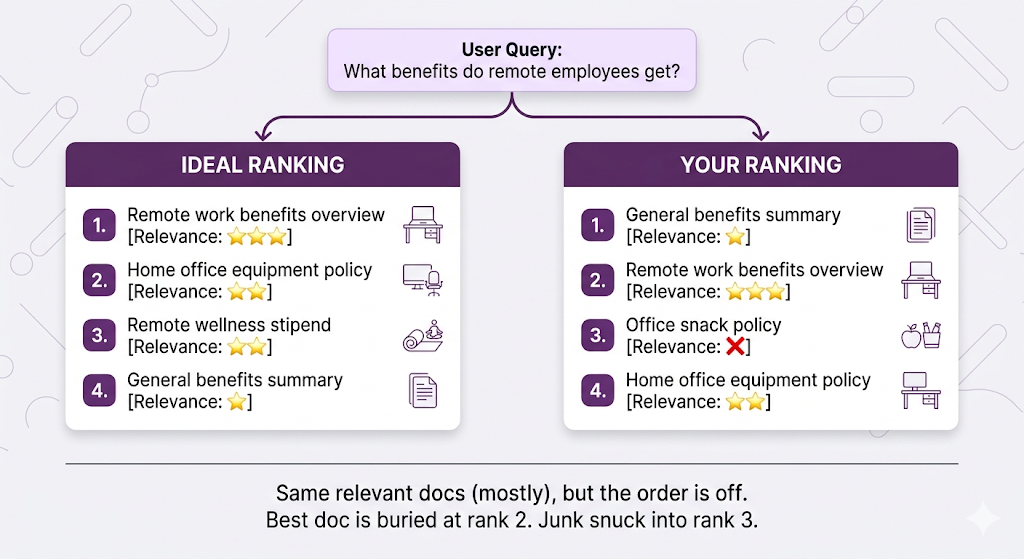
The metric for this is Normalized Discounted Cumulative Gain (NDCG) how good is your entire ranking, accounting for both relevance AND position?
Yeah, the name is a mouthful. But the concept is intuitive:
- Score each document by relevance (0 = trash, 3 = perfect match)
- Positions matter rank 1 is worth more than rank 5
- "Discount" relevant docs that appear too late (penalty increases the further down they are)
- Normalize everything against what the perfect ranking would score
NDCG range: 0.0 to 1.0
1.0 = Perfect ranking (most relevant docs on top, in the right order)
0.5 = Mid ranking (relevant docs exist but poorly ordered)
0.0 = Absolute trash ranking
The key insight: The penalty is bigger when highly relevant docs are ranked low. Having your best doc at rank 5 hurts way more than having a so-so doc at rank 5. NDCG captures that asymmetry. MRR doesn't.
When NDCG matters: Complex questions needing multiple documents, research systems, anything where the user needs a comprehensive answer drawn from several sources.
Quick Reference: Which Retrieval Metric Do I Care About?
Stage 2: Is the LLM Doing Its Job?
Okay so your retrieval crushed it you grabbed the perfect documents. But that doesn't guarantee the LLM will stick the landing.
New failure modes unlocked.
Failure Mode 5: Making Stuff Up (The Hallucination Problem)
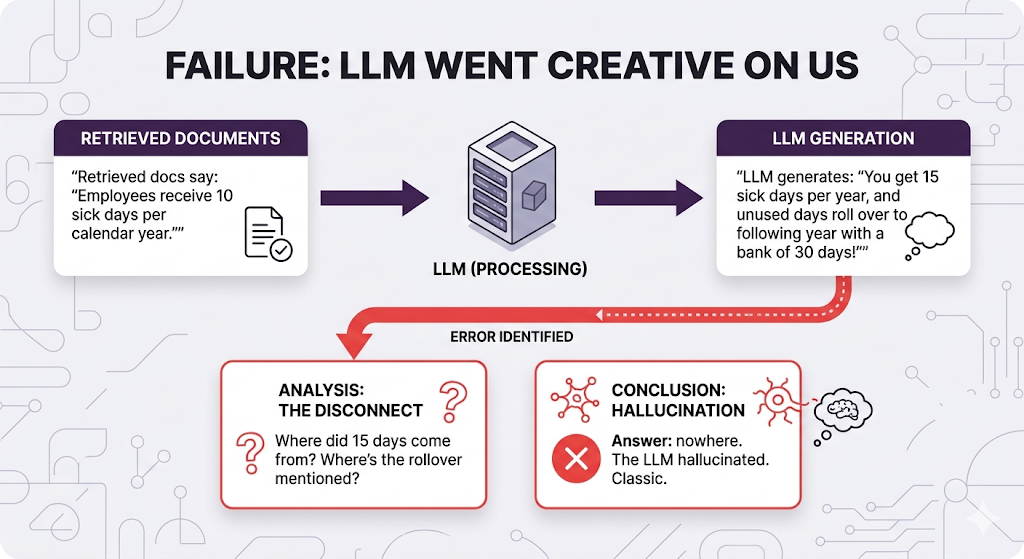
The metric for this is Faithfulness is the answer actually grounded in the retrieved documents, or did the LLM just improvise?
This is genuinely hard to measure automatically because you need to check if each claim in the answer appears in the source docs, verify no contradictions or fabrications, and confirm nothing was injected from the LLM's training data.
Common measurement approaches:
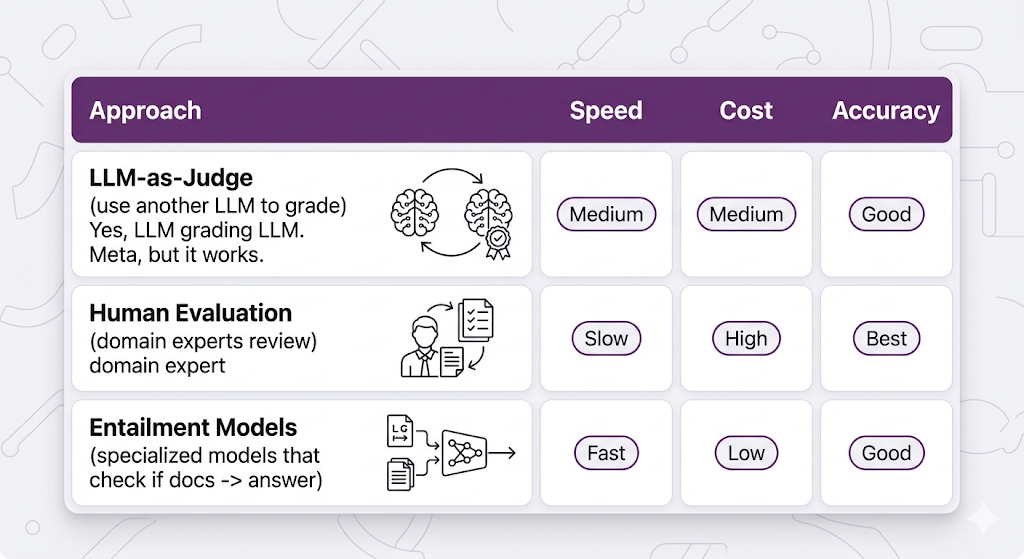
Faithfulness score: 0.0 to 1.0
1.0 = Every claim is directly supported by retrieved docs
0.7 = Mostly accurate but some unsupported details snuck in
0.3 = Lots of hallucination mixed with facts
0.0 = Completely fabricated / contradicts the sources
Failure Mode 6: Technically Accurate but Useless
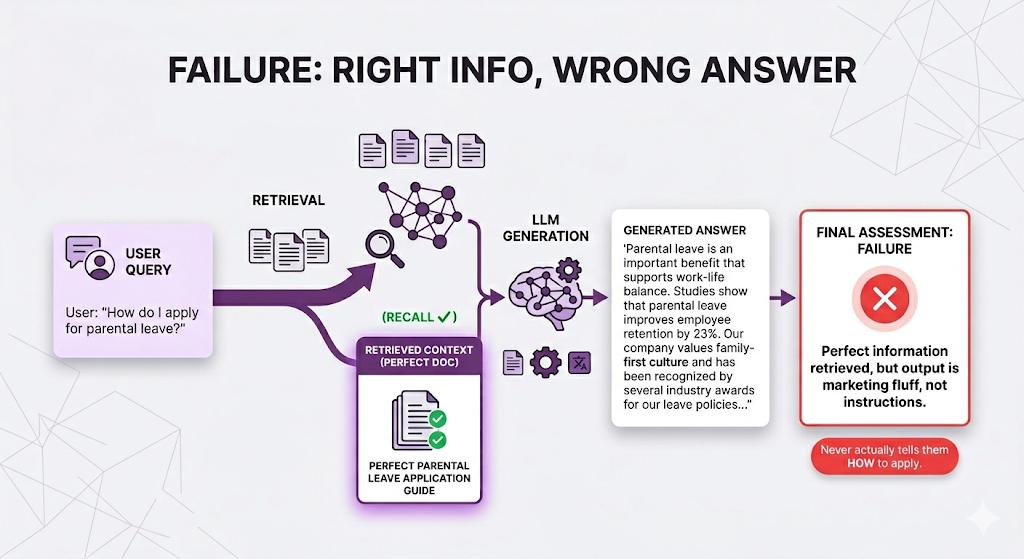
The answer is faithful (nothing was made up), but it's not relevant to what the user actually asked. They wanted the steps. They got a PR statement.
The metric for this is Relevance does the answer actually address the user's question?
Relevance score: 0.0 to 1.0
1.0 = Directly answers the question asked
0.7 = Partially answers but goes on tangents
0.3 = Mostly off-topic
0.0 = Completely irrelevant to what was asked
The Faithfulness vs. Relevance Tension
Sometimes these two metrics fight each other. This is one of the trickiest trade-offs in RAG:
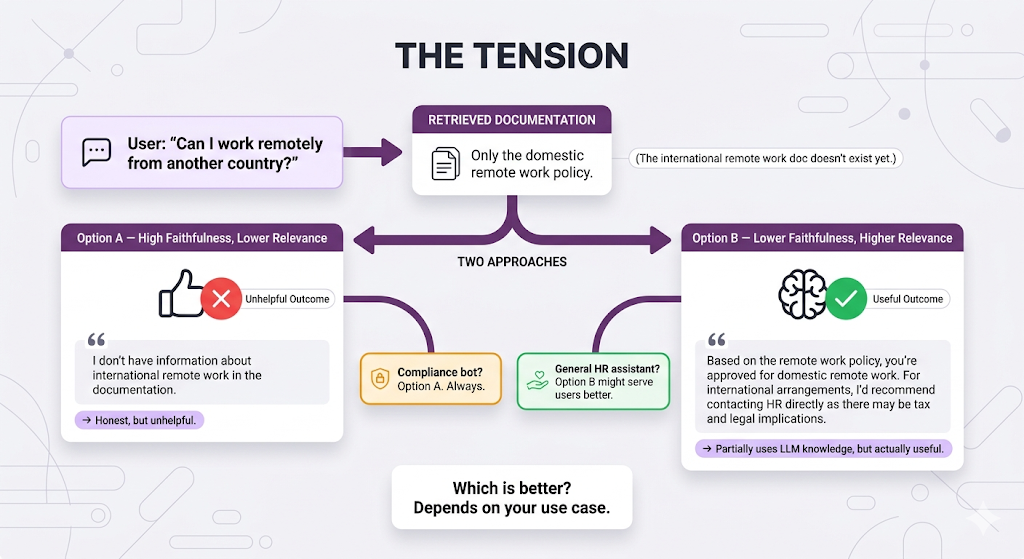
Generation Metrics at a Glance

Faithfulness and Relevance are the big two. Get those right first. Completeness and Conciseness are polish important, but don't optimize for them until the fundamentals are solid.
Building Your Eval Dataset: The Ground Truth Problem
Okay so you understand the metrics. You know what to measure and why. Now the hard part: how do you actually measure them?
You need ground truth the "right answers" to compare your system against.
The Cold Start Problem
You: "Let me check my retrieval precision!"
Also you: "Wait... which documents SHOULD have been retrieved?"
You: "...I actually have no idea."
This is the ground truth problem. You can't measure accuracy without knowing what "accurate" looks like. It's like grading an exam without an answer key.
Three approaches, each with different trade-offs:
Approach 1: Expert Annotation (The Gold Standard)
Get humans ideally domain experts to create evaluation datasets.
For each test query, you need: which documents should be retrieved (ground truth retrieval), what the ideal answer should say (ground truth answer), and which facts are essential vs. nice-to-have.
For our HR system, that means getting the actual HR team to sit down and say "when someone asks about sick leave for part-time employees, these are the three docs that should come back, and this is what a good answer looks like."

Approach 2: Synthetic Data Generation (The Scrappy Approach)
Use LLMs to generate your eval dataset:
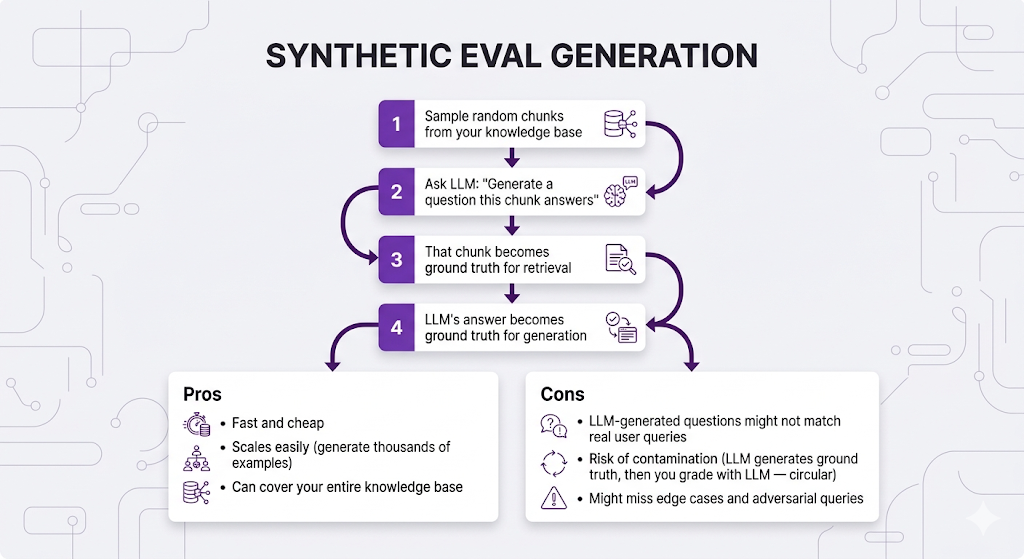
Approach 3: Production Logging + Human Feedback (The Move)
Build your eval dataset from real usage:
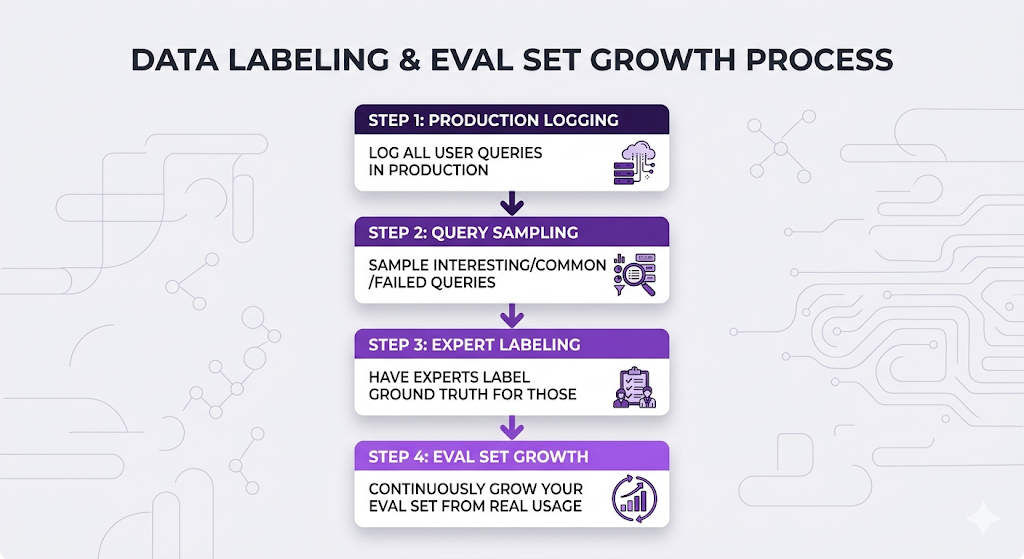
This is the move because you get real user queries (not synthetic), you focus on actual usage patterns instead of imagined ones, and it grows over time as new edge cases surface. The distribution of your eval set naturally matches the distribution of your actual users.
The Winning Strategy: Combine All Three
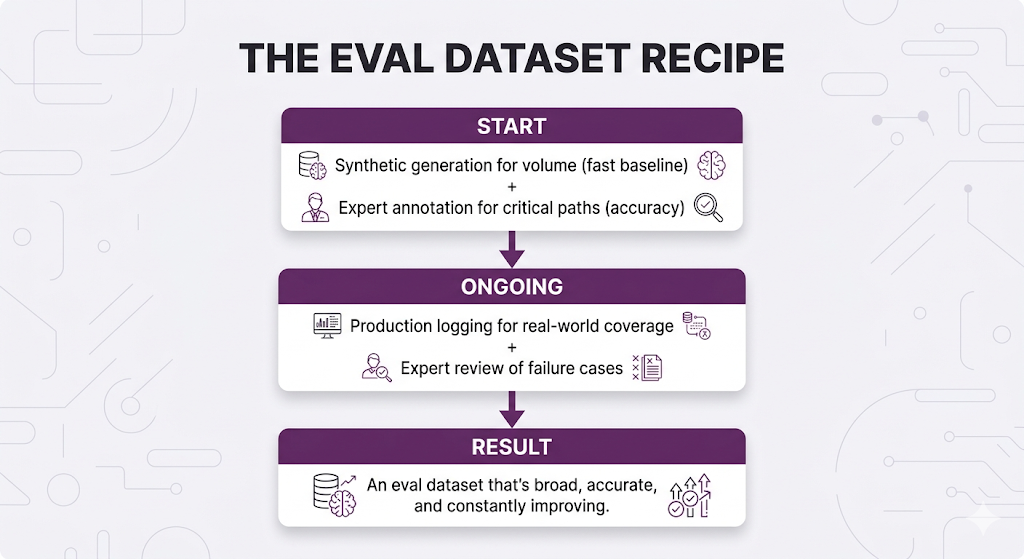
Structuring a Balanced Eval Dataset
Don't just randomly sample queries from production. Be strategic about what you include:

A/B Testing: The Scientific Method for RAG
You've got your metrics. You've got your eval dataset. Now you can actually test if changes improve anything instead of just vibes-checking it.
The Experiment Framework
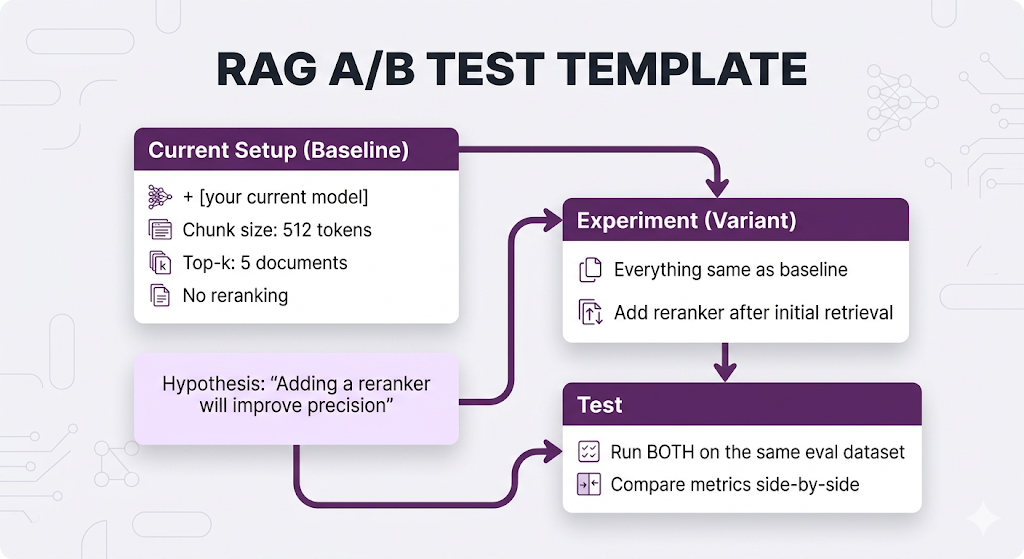
What to A/B Test

The golden rule: Change ONE thing at a time. If you swap the embedding model and the chunk size and add a reranker all at once, you have no idea which change caused the improvement (or regression).
Reading A/B Test Results
Let's say you tested adding a reranker:

The Regression Trap
You: "Sweet, my new embedding model improved recall by 10%!"
Also you: "Wait, why did faithfulness drop by 15%?"
Always check ALL metrics. Optimizing for one thing often tanks another. This is the single most common mistake teams make they celebrate a win in one metric without noticing they created a regression somewhere else.
Common trade-offs to watch for:
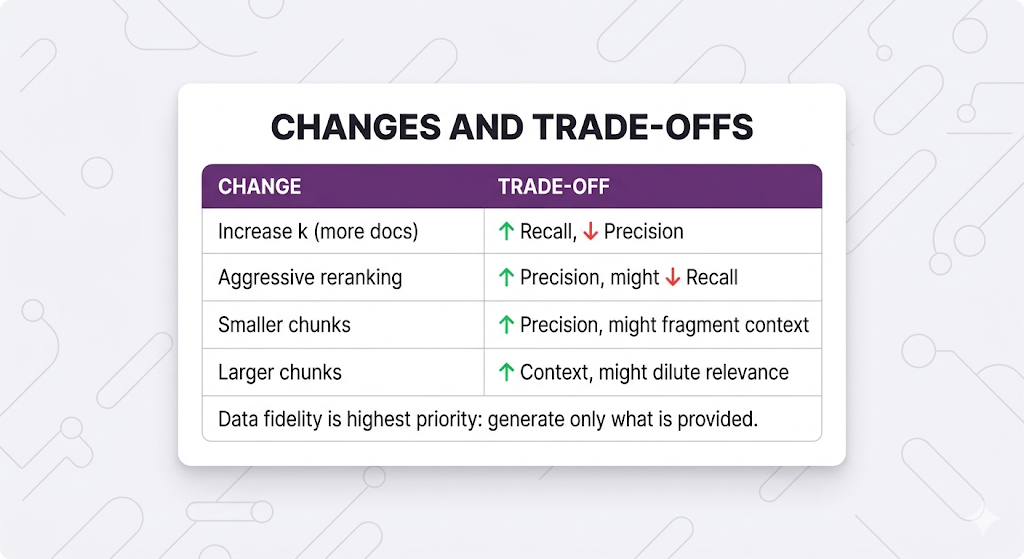
Production Monitoring: Quality Control That Never Stops
You shipped your RAG system. Metrics looked great in testing. You're done, right?
Nah. Production is where the real chaos starts.
Why Systems Drift
Month 1: Working perfectly ✅
Month 3: Starting to feel mid 😐
Month 6: Actively bad 💀
What happened?

Without monitoring, you don't notice until users start complaining. With monitoring, you catch drift early and fix it before it tanks.
The Three-Layer Monitoring Strategy
Think of this like quality control in a factory you don't just inspect the final product. You monitor at every stage.
Layer 1: Automated Metrics (Real-Time)
Track these for every query in production:
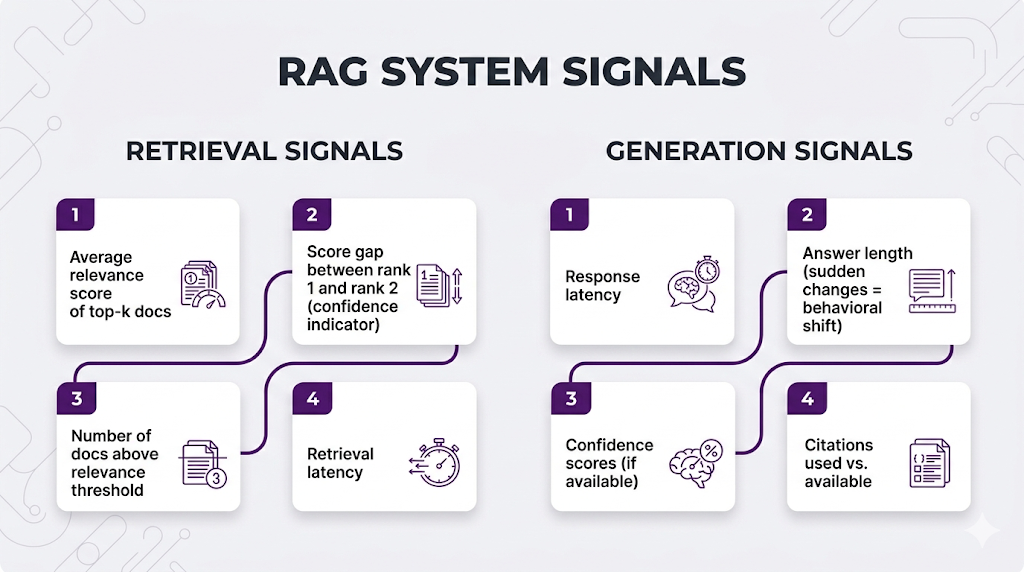
Red flags to alert on: sudden drop in average relevance scores, increasing latency, answers getting way longer or shorter than usual, spike in "I don't know" responses.
Layer 2: Sampled Human Eval (Weekly/Monthly)
You can't human-review every query, but sample intelligently:
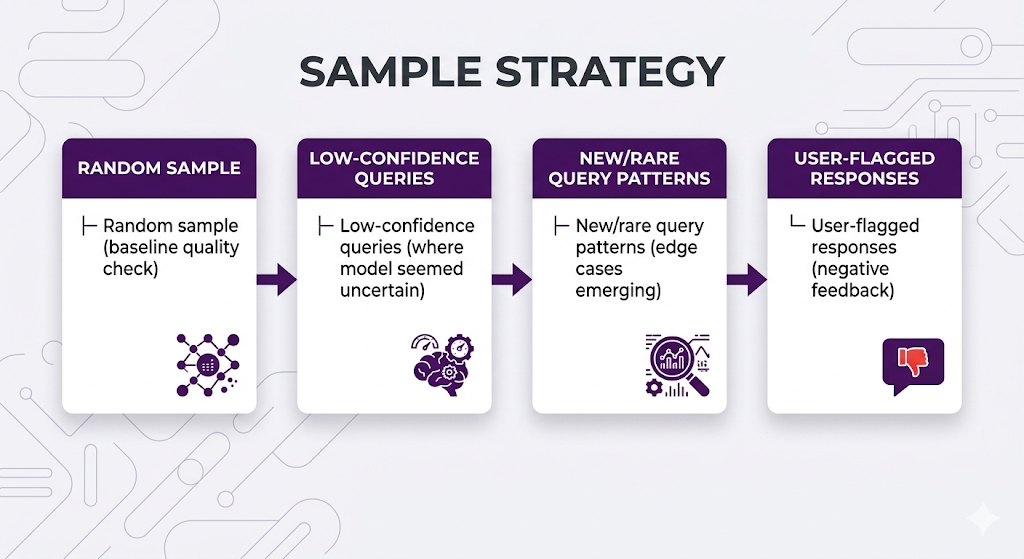
Have humans rate retrieval quality (right docs?), answer quality (accurate? helpful?), and failure modes (what went wrong?).
Layer 3: User Feedback Loops (Continuous)

The Health Dashboard
What you should be looking at every week:
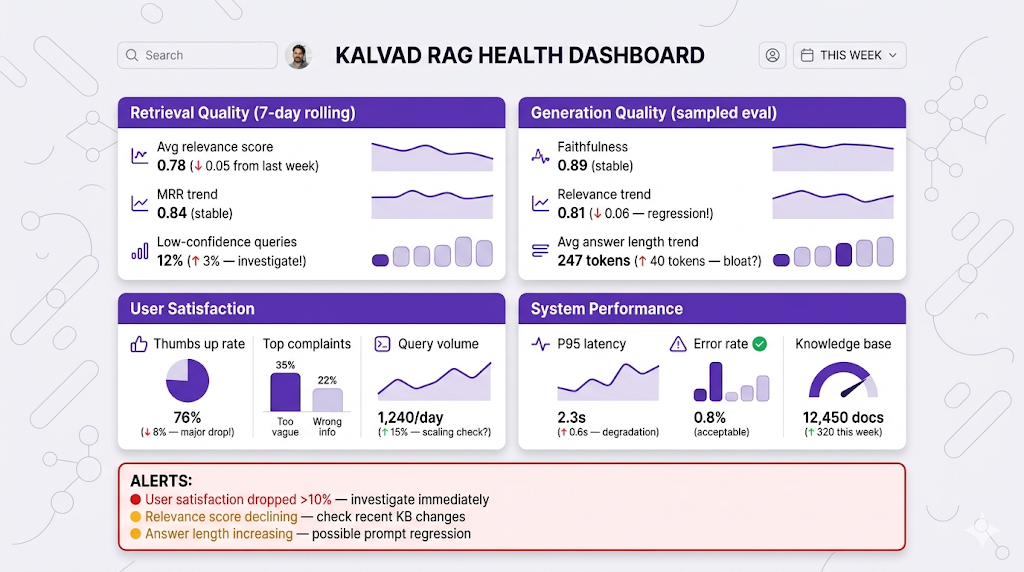
When to sound the alarm:
- Sudden drop in any metric (>10% in a week)
- Consistent degradation trend (slow decline over months)
- User satisfaction tanks (thumbs down >30%)
- Latency doubles without explanation
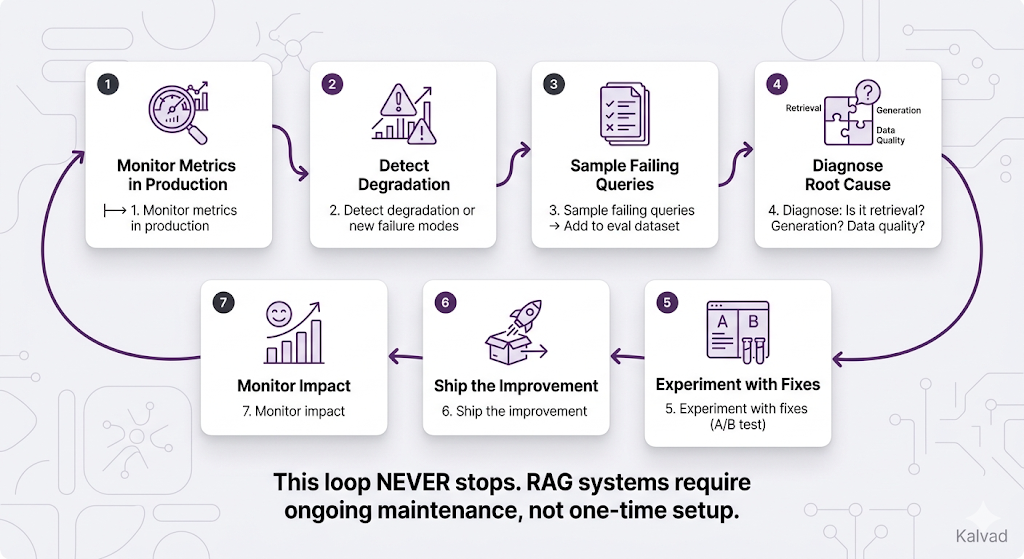
The Continuous Improvement Loop
This is the part most teams miss. Evaluation isn't a one-time event it's a permanent loop:
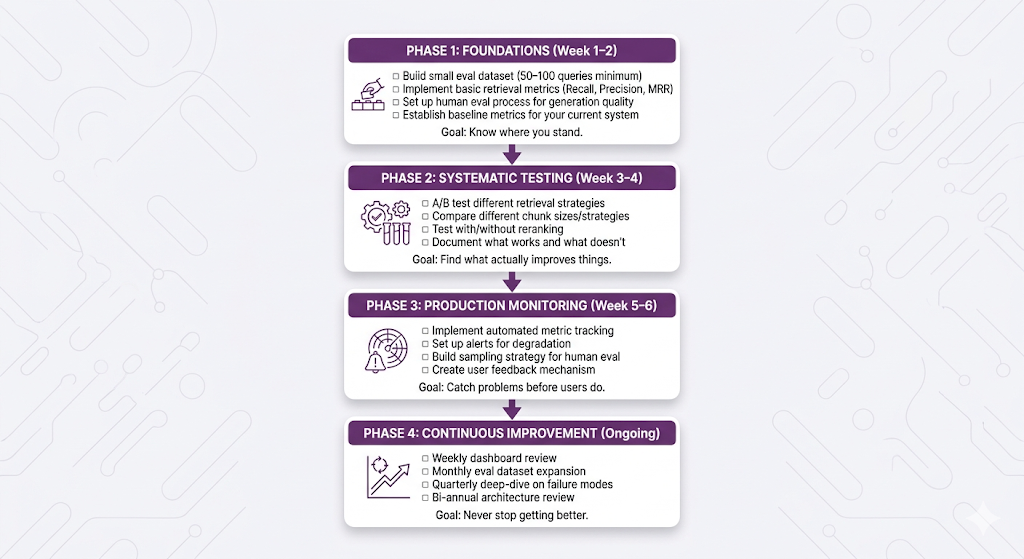
Your Evaluation Roadmap
Here's a practical phased rollout. Don't try to do everything at once.
Key Takeaways
Mental Models to Remember
MENTAL MODEL #1: The Two-Stage Diagnostic
When something goes wrong, ALWAYS ask two questions:
1. Did retrieval find the right documents?
2. Did the LLM use them correctly?
The answer tells you exactly where to focus your fix.
Don't optimize generation when retrieval is the problem.
MENTAL MODEL #2: Different Metrics, Different Stories
Recall: "Did we find everything?"
Precision: "Did we avoid the noise?"
MRR: "Did we surface the best doc first?"
NDCG: "Is the full ranking any good?"
Faithfulness: "Did we stay grounded in the sources?"
Relevance: "Did we actually answer the question?"
Each metric catches a different failure mode.
Track all of them. Optimize for the ones that matter
most for YOUR use case.
MENTAL MODEL #3: Evaluation Is a Loop, Not a Destination
Build → Measure → Identify failures → Fix → Measure again.
Your eval dataset should grow every single week.
Your metrics should be tracked every single day.
Your system should be improving every single month.
The day you stop evaluating is the day your system
starts degrading.
MENTAL MODEL #4: Start Simple, Earn Complexity
50 expert-labeled queries > 5000 synthetic queries
you never look at.
A simple thumbs up/down button > an elaborate
evaluation framework you never ship.
Basic recall + precision + faithfulness > twelve
custom metrics nobody understands.
Start with what you can actually maintain.
The Golden Rule
┌─────────────────────────────────────────────────────────────────┐
│ │
│ "You can't improve what you don't measure." │
│ │
│ But also: you can't measure what you don't understand. │
│ Learn the metrics. Build the eval set. Ship the monitoring. │
│ And then never stop iterating. │
│ │
└─────────────────────────────────────────────────────────────────┘
The Full Journey: Series Wrap-Up
That's it. Eight posts. The full RAG lifecycle, from "should I even use RAG?" to "how do I keep it running in production."
Let's zoom out and see how everything connects:
The Complete RAG Architecture (All 8 Posts)
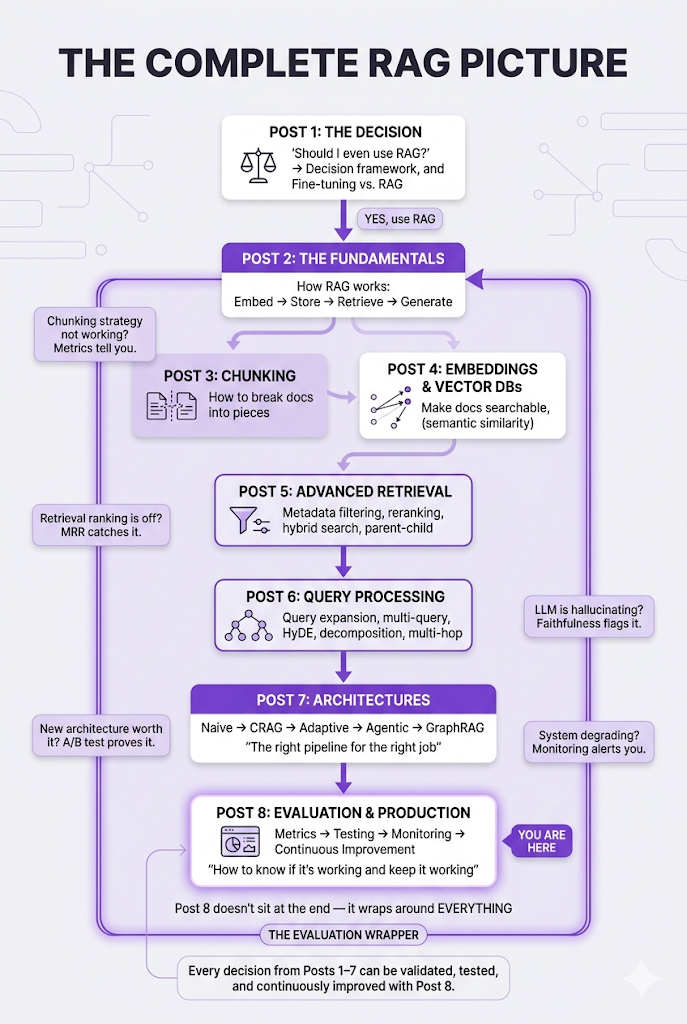
The Complete Series
Here's what you've built, post by post:
- Post 1: Why RAG: the decision framework
- Post 2: How RAG works: the fundamentals
- Post 3: How to chunk: breaking documents into searchable pieces
- Post 4: How to search semantically: embeddings and vector databases
- Post 5: How to search better: advanced retrieval techniques
- Post 6: How to ask better questions: query processing strategies
- Post 7: How to architect the whole system: RAG architectures
- Post 8: How to know if it's working: evaluation and production
A Personal Note
When we started this series, the goal was simple: explain RAG the way I wish someone had explained it to me. No code-first tutorials that skip the "why." No papers that assume you already know what NDCG stands for. Just honest, progressive, concept-first education that respects your time and your intelligence.
Eight posts later, you have the complete picture from "should I even use RAG?" all the way to "how do I keep it running at 2 AM when my metrics dashboard lights up." Every concept builds on the last. Every analogy carries forward. And every trade-off is laid out honestly, because there are no silver bullets in this space only informed decisions.
If this series helped you understand RAG better, that's the whole point. Go build something real with it.
And if you're stuck on any of it? You know where to find me.
Ready to Build Your RAG System?
We help companies build production-grade RAG systems that actually deliver results. Whether you're starting from scratch or optimizing an existing implementation, we bring the expertise to get you from concept to deployment. Let's talk about your use case.
Part 8 of the RAG Deep Dive Series | The Finale