- We’re introducing Instantaneous PowerLoss Storm, a new testing paradigm within Meta’s infrastructure for handling and mitigating instant or zero-notice power loss in our data centers.
- We’re sharing: how we built readiness to tolerate instant failures into our existing systems with defense-in-depth strategies; tradeoffs made in implementing it, and how we validated our readiness.
Disaster preparedness is not optional. Hurricanes, wildfires, power supply and network disruptions, and countless more disaster scenarios all pose risks to our data center (DC) infrastructure.
Early warning systems and tried-and-tested mitigation strategies already serve us well in situations where we have a few hours or more advanced warning. While these strategies have matured over time as we have expanded our DC presence, the ever-increasing size and variety of our infrastructure has demanded an increased level of preparedness for zero-notice disasters (ones that occur without any warning), such as instantaneous power loss, with minimal impact to overall fleet availability.
Instantaneous PowerLoss Storm is a new testing paradigm within Meta’s long-established Disaster Readiness (DR) “Storm” program that forms the last line of defense, and the ultimate safety net, to handle and mitigate instant or zero-notice power loss from known, emerging, and unknown risks.
How We Built Readiness To Tolerate Instant Failures Into Our Existing Systems With Defense-in-Depth Strategies.
 The capability to handle instant power loss had to be built from the ground up into our DC stack, from mechanical and electrical facilities to server racks, from storage to compute and the core Twine container orchestrator. Fortunately, each of these architectures was already developed with power loss tolerance as an integral component.
The capability to handle instant power loss had to be built from the ground up into our DC stack, from mechanical and electrical facilities to server racks, from storage to compute and the core Twine container orchestrator. Fortunately, each of these architectures was already developed with power loss tolerance as an integral component.
Providing the ability to persist in-memory data when racks have lost power using batteries and Power Loss Siren (PLS) is one such capability. Having a robust DC region-wide asynchronous signaling mechanism for Twine services in the form of unavailability events (UE) is another. (A DC region — referred to as a “region” below — is one where multiple DC buildings are co-located and share common network and power connectivity).
While these abilities were battle-tested and hardened on singular fault domains within single DCs, we identified outstanding vulnerabilities in scenarios encompassing an entire region. Also, testing a region required us to confront problems of not only scale (a typical region is normally 50-60x the size of the typical fault domains) and replica placement, but also of autonomous bootstrapping.
Bootstrapping refers to kickstarting a powered-off region and requiring millions of services to start all at once and discover each other autonomously. We describe two of the problems we encountered with bootstrapping below that required us to adopt a belt-and-braces approach to cover all possible eventualities and contingencies.
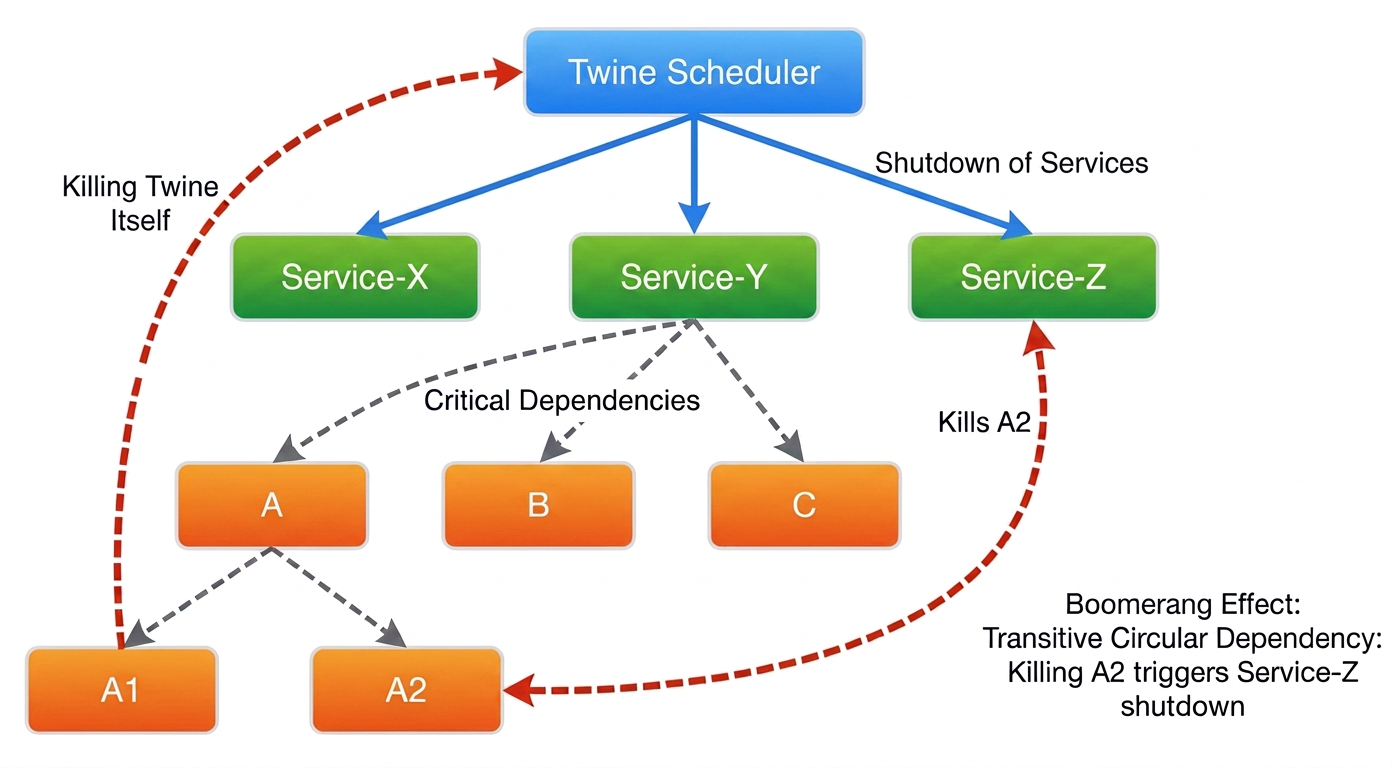
A prominent one to call out — one that haunted us from our earliest days — is that of dependencies, and in particular the dreaded circular dependency, “ouroboros,” risk! Our Twine orchestrator has a set of control plane services — Scheduler, Allocator, Broker, Zelos (co-ordinator), and so on — without which we cannot run or start any other services in the region. While the risk from circular dependencies during regular operations is low, the risk and impact are far higher when bootstrapping an entire region. It’s a true chicken and egg problem.
We solved this by identifying critical startup dependencies among the control plane services, and we continuously detect those early and often with Belljar tests in our CI / CD pipelines. These helped uncover and eliminate most, if not all, dependency risks before they are deployed to production. Given the rapid evolution of our Infra, and as a belt-and-braces solution, we also required the capability to break any circular dependencies that may have unexpectedly occurred. A purpose-built Twine recovery kit provides this “jumpstart” capability to recover those Twine services that power Twine itself. Together with Belljar and Twrko, we have been able to successfully put the specter of circular dependencies to rest.
We also encountered a “boomerang” problem in the same vicinity — the generator of a critical signal being impacted by the same signal. The UEs used to orchestrate shutdown and recovery of services ended up shutting down the orchestrator control plane services themselves, resulting in orphaned services that could not be “reaped” (because they never received a UE). While this problem could have been solved with intricate solutions such as excluding a preset set of services from the UE dispatch list, we decided to adopt a simpler and more sustainable approach by allowing control plane services to simply “ignore” shutdown signals associated with power-related UEs.
Tradeoffs Made When Striking the Right Balance Between Reliability and Velocity of Growth.
While it is feasible to build watertight tolerance to instant loss, this can come at opportunity costs for infra or risk overengineering our systems. The latter even has the potential to introduce risks of false positives impacting regular operations. Hence, we needed to make certain tradeoffs to strike the right balance between reliability and engineering.
We began by drawing the line on which impacts must be avoided. Data loss of storage and database systems, permanent damage to DC facilities (mechanical/electrical), or sustained impact beyond a single region are some that we prominently noted as table-stake requirements. Transient service errors, rack failures (within a predefined threshold), and bounded staleness in service routing tables or in region unavailability detection (this is a hard problem for asynchronous systems) were deemed as tolerable risks. In general, only issues which cannot be mitigated through post-incident remediations, and within a reasonable mean time to respond (MTTR), fell outside the boundary of tolerable impact.
How we validated our readiness through the exercise of Instantaneous PowerLoss Storm, and how this is enabling us to push the envelope further.
Validation of the above expectations and preparation, by de-energizing a large production region, carried significant risks with several known and unknown unknowns. To solve this chicken-and-egg problem of needing to take risk to address risk, we established an incremental approach where we validated self-contained problems such as dependencies when turning up new/pre-production regions, as well as by running tests in “shadow” regions which replicate production regions. Subsequently, we were able to successfully test in our newest (and thus smallest) production regions with limited blast-radius. Finally, we powered off large production regions housing critical storage, AI, and data warehouse workloads. At this stage, we named these Storm exercises Instantaneous PowerLoss Storms.
From 10,000 feet, the Storm consists of a power supply fault being injected to cause immediate de-energization of the entire region, and after a short MTTR remedial “drain” actions undertaken to cordon off the impacted region from global controllers/schedulers. We also aimed to avoid undertaking any preemptive actions prior to the test to truly represent an unexpected loss of power. MTTR chosen for the test mirrored typical MTTR seen during real incident scenarios.
Each of these exercises helped to train our infrastructure and engineers iteratively towards the long term goal of handling loss of a region as seamlessly as loss of a sub-regional fault domain.
Stepping Stones Into the Future: Slow is Smooth. Smooth is Fast
Even with all precautions, this has not been an entirely smooth path but one with multiple opportunities for learning and improvement that not only improved our testing capability but also pervaded throughout our Infra with several architectural improvements to our existing systems.
In tandem, our infra has been evolving rapidly to meet myriad use cases of capacity and AI. Moving fast is possible only when we have strong foundations. Reliability and velocity are two facets of the same coin. You cannot have one without the other. The ability to recover a region from instantaneous failure has laid a strong foundation that has helped enable us to innovate in DC designs and validate them, build reliability in lockstep with rapid capacity deployments, and push the envelope further in what risks we can tolerate.
While previous Storms mostly validated storage and database backends, we are adopting the same incremental strategy towards validating regions with live client traffic against instantaneous failures. (More on this in an upcoming post!) We are also continually revisiting and revising tradeoffs in light of new challenges emerging during this growth phase.
The post Lights Out, Systems On: Validating Instant Power Loss Readiness appeared first on Engineering at Meta.